

ก่อนอื่นเราต้องรู้ก่อนว่าการศึกษา AI ให้เชี่ยวชาญมีหลายระดับ และเราต้องตั้งเป้าให้เหมาะสมกับเป้าหมายของเราเอง

ลำดับถัดมาก่อนที่เราจะเจาะลึกหัวใจของ AI เรามาดูประวัติความเป็นมากันครับ

ปฐมบท AGI: AI มาถึงจุดนี้ได้อย่างไร
เข้าสู่ตอนแรกของ Transformers Series, โมเดลที่เป็นหัวใจของ AI ในท้องตลาดทุกตัวไม่ว่าจะเป็น ChatGPT, Gemini, Claude, etc.
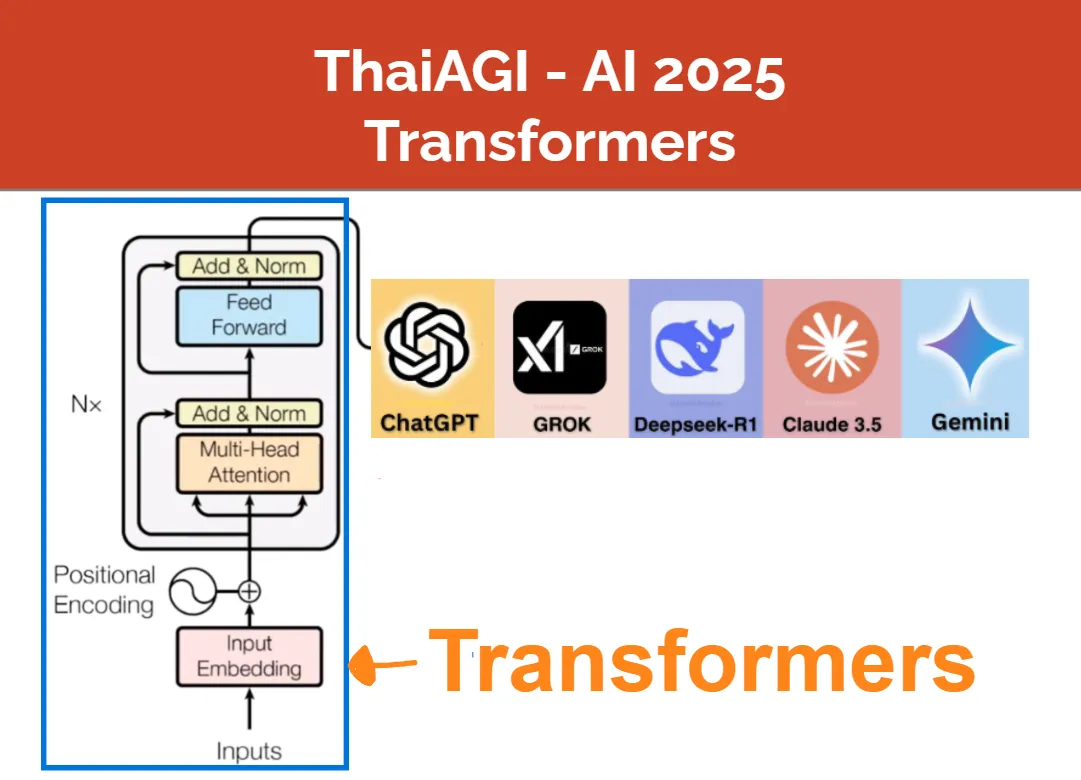
Transformers หัวใจของ ChatGPT
จากบทความ “ปฐมบท AGI” เราได้เห็นแล้วว่า โมเดล AI ที่ปฏิวัติเทคโนโลยีโลกไม่ว่าจะเป็น ChatGPT หรือ Gemini ล้วนมีโมเดลที่ชื่อว่า Transformers เป็น “สมอง” หรือ “ความฉลาด” ตัวจริงของ AI เหล่านี้
GPT ก็ย่อมาจากคำว่า Generative Pretrained Transformers และแท้จริงแล้ว ChatGPT เป็นโมเดลที่อัพเกรดจาก Transformers มาเล็กน้อยเท่านั้น หัวใจสำคัญยังอยู่ที่ Transformers
ใน ThaiAGI Transformers Series เราจะมาทำความรู้จัก Transformers กันอย่างละเอียด โดยบทความนี้เป็นจุดเริ่มต้นของ Series นี้และจะประกอบไปด้วยสี่หัวข้อหลัก ที่เชื่อมโยงกันดังนี้ครับ
-
(เกือบ)ทุกปัญหาที่ AI แก้ มาจากปัญหาง่ายๆ ที่เรียกว่า “Classification” หรือ “ปัญหาการแบ่งประเภทวัตถุ” ซึ่ง Transformers ก็มาแก้ปัญหานี้เช่นกัน โดยมุมมอง classification นี้สามารถขยายไปสู่ปัญหาการพูดโต้ตอบในภาษามนุษย์ของ ChatBots ทั้งหลายได้
-
ในปัญหา classification ง่ายๆ AI สมัยก่อน เราใช้ 2.1 (ขั้น I) Feature Extraction) “ความรู้มนุษย์” สร้าง Features โดยแต่ละ feature แทนการวัดค่าบางอย่างจากวัตถุ 2.2 (ขั้น II) Linear Model ลากเส้นแบ่งวัตถุแต่ละกลุ่มออกจากกัน
-
ในวัตถุที่ซับซ้อนเช่น “ภาษามนุษย์” ที่เราต้องการให้ AI เข้าใจ (ขั้น I*) ตีความหมาย Features ใหม่ โดยใช้การตีความว่า feature คือ “ทิศทางใน vector space” (ขั้น II*) ตีความหมาย Linear Model ใหม่ เปลี่ยนจากการมองเป็นการลากเส้นแบ่ง เป็นการ “หา vector ในทิศทางที่เหมาะสม”
-
ทำความรู้จัก “ภาพรวม” ของส่วนประกอบหลักในโมเดล Transformers —> Neural networks, Attentionsม Embedding และอื่นๆ ซึ่งจะลิงก์ไปบทความถัดไปของ ThaiAGI Transformers Series ที่จะอธิบายส่วนประกอบทุกชิ้นของ Transformers อย่างละเอียด
ตอนที่สองของ Transformers Series ที่เราจะมาเจาะลึกวิธีเก็บ "ความทรงจำ" ของ AI
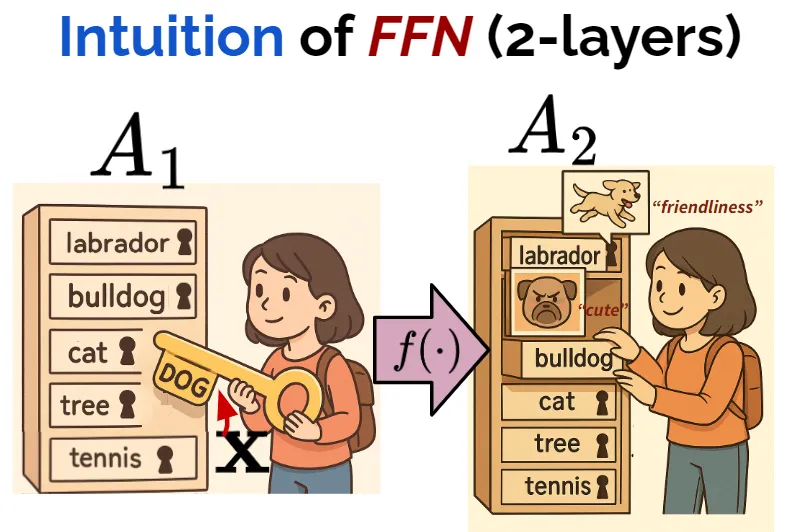
FFN และ Superposition มหัศจรรย์ "ความจำ" (Memory) ของ AI
โดยในบทความนี้เราจะเจาะลึกในสองบล็อกพื้นฐานที่สุดและปรากฏการณ์ที่เกี่ยวข้องดังนี้
-
ดูหลักการ Input Embedding (บล็อก A) เบื้องต้นในขั้นแรกสุดของการเปลี่ยน “คำ” ให้เป็น “เวกเตอร์”
- ขั้นตอน Input Embedding นี้ทำอย่างไร และมีโค้ดทีเรียกใช้งานอย่างไร
- ในเมื่อบล็อก A นี้เราได้เวกเตอร์แล้ว ทำไมยังจำเป็นต้อง “ปรับปรุง” เวกเตอร์ให้ดีขึ้นไปอีกในขั้นถัดไป การ “ปรับปรุง” เวกเตอร์ให้ดีขึ้น คืออะไรกันแน่?
-
เจาะลึก FFN (บล็อก D) ซึ่งจะทำให้เราเข้าใจว่า Transformers หรือ ChatGPT - “จำ” ความรู้ต่างๆ และ “ดึงความรู้” ผ่านหลักการ “feature-as-direction” และ สมการ Linear Models ได้อย่างไร - (เชื่อมโยงกับหัวข้อ 1.) ความรู้ที่ถูกดึงจาก FFN จะถูกนำไป “ปรับปรุง” ให้เวกเตอร์ input ดียิ่งขึ้นอย่างไร
-
ทำความรู้จักปรากฏการณ์ “Sparsity” และ “Superposition” - Sparsity คืออะไร? และ Superposition คืออะไร? - โดยสองปรากฏการณ์นี้ทำให้ FFN นั้น “เรียนรู้” หลักการ “feature-as-direction” ได้ด้วยตัวเองและ “จำความรู้” ได้ประสิทธิภาพสูงสุด ด้วยการบีบอัดหลายเวกเตอร์จำนวนมากกว่ามิติใน vector space ถึงแม้ feature vector เหล่านั้นจะไม่ตั้งฉากกันโดยสมบูรณ์
AI Alignment และปัญหาการประจบ ข่มขู่ โกงและลวงโลกของ AI
AI Alignment มีเป้าหมายที่ต้องการให้ AI และ “มนุษย์ผู้สร้างโมเดล” มีจุดมุ่งหมายและคุณค่าที่ตรงกัน แต่การ align เป้าหมายให้ตรงกันนี้ยากกว่าที่คิดอย่างมาก และเป็นตัวแปรสำคัญที่จะกำหนดว่า AI ในอนาคตจะเป็นอันตรายต่อมนุษย์หรือไม่ อ่านบทความฉบับเต็มที่นี่

