

Lab จาก MIT ปฏิวัติความเข้าใจเรื่อง “สิ่งที่ AI เห็น” สวัสดีครับเพื่อนๆ สัปดาห์นี้ขอเปลี่ยนบรรยากาศจากว่าด้วยเรื่อง Programming หรือ Frontier Applications มาว่ากันด้วยเรื่อง AI Fundamental กันบ้างนะครับ โดยสิ่งที่เราสนใจก็คือ “เวลา AI ทำนายสิ่งต่างๆ เช่น ทำนายภาพของสุนัข/รถยนต์ ว่าเป็น สุนัข/รถยนต์” นั้น โมเดลรู้ได้อย่างไร และพิจารณาจากองค์ประกอบไหนในรูป ในปี 2018-2019 Lab จาก MIT ได้ทำงานวิจัยปฏิวัติความเข้าใจเรื่องนี้ให้คนในวงการหลายเรื่อง โดยขอเล่าย้อนจากต้นกำเนิดก่อนครับ
คำอธิบายในช่วงเริ่มต้น (2012-2013)
ในช่วงเริ่มต้นของ Deep Learning (2012-2013) เราเชื่อกันว่าโมเดล Deep Learning ที่มีความลึกสูงจะช่วยสกัด Features ที่มีความหมายออกมาได้ เช่น ในการทำนายรูป “สุนัข” โมเดลก็จะทำนายจาก Features ที่เป็น “หู” “ตา” “จมูก” “ขน” ฯลฯ ซึ่งเป็นวิธีการคล้ายๆ กับที่มนุษย์ใช้จดจำ (ดูรูปแนบ และอ่านเพิ่มเติมได้จากบทความประวัติย่อของ Deep Learning ที่แนบด้านล่าง)

ภาพจากสไลด์ของ Le Cun (หนึ่งในบิดาของ Deep Learning) ที่อธิบายเรื่องสิ่งที่ DL Model เห็นใน ICML 2013 โดยกล่าวว่า ใน layer ที่ลึกมากๆ ขึ้นเรื่อยๆ นั้นจะสร้าง Features ที่มีความหมายมากขึ้นเรื่อยๆ เช่น จากภาพรถยนต์
- ใน layer แรกๆ โมเดลจะจับได้แค่เส้นชนิดต่างๆ
- ใน layer กลางๆ จะเริ่มนำเส้นต่างๆ มาเชื่อมต่อกันเป็นลาย และวัตถุง่ายๆ
- ใน layer หลังๆ (ลึก) โมเดลจะเริ่มเข้าใจวัตถุที่ซับซ้อน (เช่นล้อรถยนต์ หรือกระจกข้าง) โดยนำวัตถุหรือลวดลายทั้งหลายใน layers ก่อนหน้ามาประกอบกัน
”สัญญาณปรปักษ์” สร้างความตะลึงไปทั่วโลกในปี 2014
อย่างไรก็ดีมุมมองนี้ก็ถูกท้าทายอย่างรุนแรงในปี 2014 โดยงานจากทีม Google AI ซึ่งเพื่อนๆ อาจเคยได้ยินกันมาบ้างแล้วเกี่ยวกับเรื่อง “การหลอก AI ให้สับสน” หรือชื่ออย่างเป็นทางการคือ Adversarial Example (ดูรูปแนบ) อาทิเช่น นำรูปของ “หมู” มาใส่สัญญาณรบกวนประเภทปรปักษ์ (Adversarial Noise) ลงไปชนิดที่คนแยกไม่ออก แต่โมเดล AI (ที่ผ่านกระบวนการฝึกสอนแบบปกติ) กลับมองว่าเป็น “เครื่องบิน” (หมายเหตุ : สัญญาณรบกวนดังกล่าวเป็นการจงใจโจมตีเพื่อทดสอบความแข็งแกร่งของระบบ (Robustness) และไม่ได้เกิดโดยบังเอิญดังนั้นจึงอาจเรียกเป็นชื่อไทยว่า “สัญญาณปรปักษ์” (Adversarial Noise) ) ดูรูปแนบเพื่อให้เห็นภาพครับ
ถ้า AI จดจำสุนัขหรือหมูจาก Features เช่น ตา หู จมูก จริงๆ ก็ไม่น่าจะเป็นไปได้ที่จะสับสนกับ Noise ที่ถูกใส่เข้าไปและทำนายเป็นเครื่องบิน ถ้าเช่นนั้นแล้วสิ่งที่ AI เห็นจริงๆ แล้วเป็นอย่างไรกันแน่??? คำถามนี้สร้างความสับสนให้กับนักวิจัย AI ทั่วโลก และได้มีหลายทีมที่พยายามหาคำตอบในเรื่องนี้ เช่น ทีม Google AI หรือทีมจากมหาวิทยาลัยชั้นนำอื่นๆ ต่างก็ตีพิมพ์คำอธิบายที่มีสมมติฐานแตกต่างกันไป (ดูอ้างอิงเพิ่มเติม) แต่ก็ไม่มีคำอธิบายใดที่ได้รับการยอมรับทั่วไป
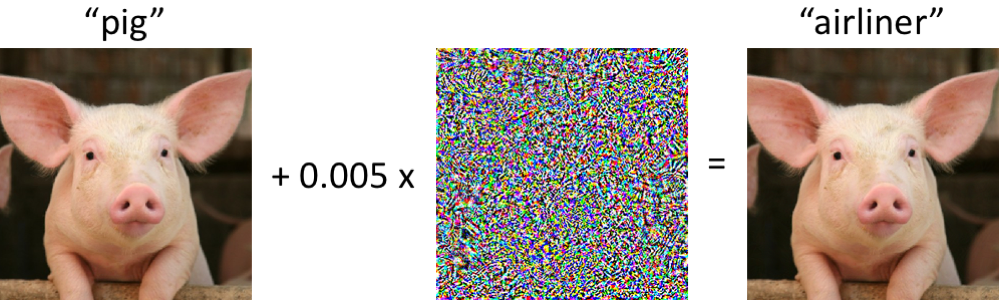
ในปี 2014 ทีมจาก Google AI ได้ค้นพบ Adversarial Noise ที่ไม่ทำให้รูปเปลี่ยนไปอย่างไรในสายตามนุษย์ แต่กลับทำให้ โมเดลทั้งหลายเข้าใจรูปต่างจากเดิมไปคนละทาง เช่น จากหมู เป็นเครื่องบิน ไม่เฉพาะรูปภาพเท่านั้น Adversarial Noise ของข้อมูลประเภทอื่นๆ เช่น เสียง (เช่น ฟังคำว่า “Like” เป็น “Hate”) ก็สามารถทำได้ทำนองเดียวกัน
งานวิจัยของ MIT ในช่วงปี 2018-2019
หนึ่งในทีมวิจัยที่ทำเรื่องนี้จริงจังคือ Madry Lab จาก MIT ซึ่งในปี 2018-2019 นี่เองได้ตีพิมพ์งานวิจัยออกมาหลายฉบับที่เกี่ยวกับเรื่อง “สิ่งที่ AI เห็น” ดังกล่าว และโชคดีมากๆ ที่ทีมนี้ได้เขียนงานเหล่านี้มาเป็น Blog ให้พวกเราได้อ่านกันอย่างง่ายๆ (ดูอ้างอิงด้านล่าง) แต่ละงานนี้้สามารถเล่าขยายความได้หลายบทความ ในบทความนี้เพื่อให้ได้เห็นภาพรวมโดยขอเล่าพอเป็นสังเขปดังนี้ครับ
1) Adversarial Examples Are Not Bugs, They Are Features : สัญญาณปรปักษ์ไม่ได้เป็นบั้กของระบบ แต่เป็น Features ต่างหาก!! งานนี้ได้ลบล้างความเชื่อว่า การที่โมเดลของเราอ่อนไหว (sensitive) กับ noise ประเภทนี้อาจเป็นเพราะโมเดลยังเรียนรู้ได้ไม่ดีพอ จึงเกิด “บั้ก” (“ข้อผิดพลาด”) ในการทำนาย งานนี้ได้ออกแบบการทดลองอย่างละเอียดและพบว่าแท้จริงแล้ว Features ของโมเดลที่เรียนรู้ได้นั้นสามารถแบ่งได้เป็น “Robust Features” ที่คล้ายมนุษย์ (หู ตา จมูก วัตถุต่างๆ) กับ “Weak Features” จำนวนมาก (ดูรูปประกอบ)
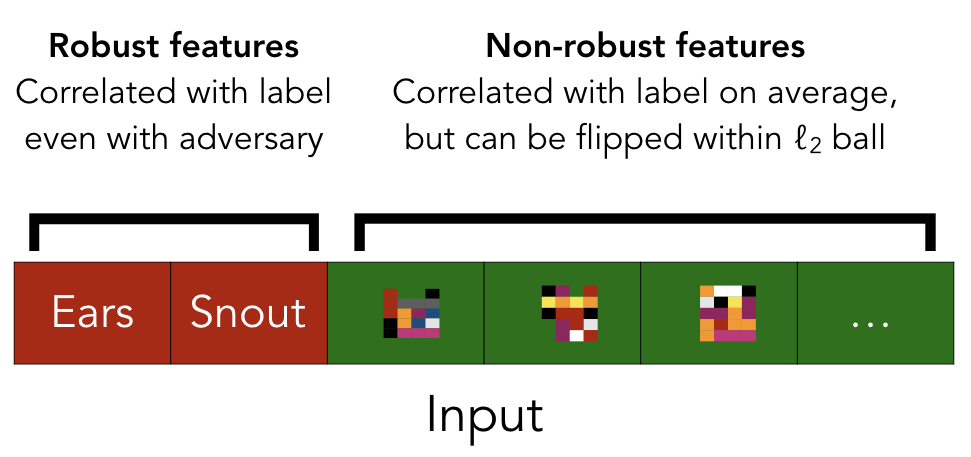
โดย Features ประเภทนี้ คือ Features ที่มีแต่คอมพิวเตอร์ที่มองออก เช่น ค่าเฉลี่ยโทนสีระดับ Pixel ในภาพ และ Weak Features นี้ช่วยให้การทำนายในสภาวะปกติ “แม่นยำขึ้น” (เป็นหนึ่งในเคล็ดลับที่ทำให้ Deep Learning ชนะมนุษย์) แต่ในขณะเดียวกัน Weak Features นี้จะสามารถถูกหลอกได้ง่ายๆ เมื่ออ่านรูปที่มี “สัญญาณปรปักษ์” อยู่ข้างใน ทำให้โมเดลทำนายผิด
ในตัวอย่างข้างบน สัญญาณปรปักษ์เกิดจากการรวมกันของ สิ่งที่ Weak Features ทั้งหมดตรวจจับ “เครื่องบิน” และถูกนำไปใส่ในภาพ “หมู” ทำให้โมเดลมองเห็นหมูเป็นเครื่องบินนั่นเอง
งานนี้อธิบายเรื่องสัญญาณปรปักษ์แบบเรียบง่ายที่สุด และสอดคล้องกับผลการทดลองที่ผ่านมาแทบทั้งหมด
2) Learning Perceptually-Aligned Representations via Adversarial Robustness : เรียนรู้ Features ที่มีความหมายบนโมเดลที่ทนทานต่อสัญญาณปรปักษ์
งานนี้ต่อยอดความคิดจากงานข้างต้น โดยออกแบบการเรียนรู้ของโมเดลใหม่ โดยบังคับให้โมเดล “โยนทิ้ง” Weak Features ทั้งหมดทิ้งไป และบังคับให้เรียนรู้เฉพาะ Robust Features เท่านั้น ซึ่งเมื่อทำการ Visualization อย่างละเอียดพบว่า Robust Features ต่างๆ มีความคล้ายคลึงกับสิ่งที่มนุษย์เห็นมากๆ เช่น หู ตา จมูก ปากของสัตว์ทั่วไป หรือ “กระดอง” ใน “เต่า” หรือ “ลาย” ของสัตว์ตระกูลแมว เป็นต้น

ตัวอย่างงานถัดมาของ Madry Lab ที่่สกัด Features บน Robust Classifier (ที่ไม่มี Weak Features แล้ว)
จากรูปแสดง Adversarial Examples ที่จะหลอกให้โมเดลทำนายผิด สังเกตว่า Adversarial Examples บน Robust Model เหล่านี้ สามารถมองออกได้ด้วยสายตามนุษย์เช่นกัน
คอลัมภ์แรก รูปต้นฉบับ คอลัมภ์ถัดไป Adversarial ของ Class กบ เต่า สุนัข ลิง แมว ฯลฯ ตามลำดับ
3) Image Synthesis with a Single (Robust) Classifier : วาดรูปใหม่จาก Classifier!
เชื่อกันว่าทุกคนคงทราบความมหัศจรรย์ของ GAN (ดูอ้างอิง) ในการสร้างสรรค์วาดรูปใหม่ๆ ที่ไม่มีอยู่จริงขึ้นมา อย่างไรก็ดีกระบวนการการฝึก GAN นั้นซับซ้อนมากๆ ในงานนี้ ทีม MIT ก็สร้างความตื่นตะลึงด้วยการแสดงว่าการสร้างสรรค์รูปใหม่ๆ นั้นสามารถทำได้ด้วยโมเดล Classifier (ทำนายประเภทวัตถุ) ธรรมดาที่ผ่านขั้นตอนการฝึกเพื่อเรียนรู้ Robust Features เพียงอย่างเดียว
นอกจากการวาดภาพใหม่ๆ แล้วงานอื่นๆ อาทิเช่น “Super Resolution” , “เติมภาพในช่องว่างที่หายไป” , “Sketch-to-Image” (เช่นเปลี่ยนภาพเสก็ตช์เป็นภาพถ่าย) และอื่นๆ ก็สามารถทำได้ดีระดับนึงด้วย Robust classifier เพียงตัวเดียวที่ไม่ได้ผ่านการฝึกเรื่องดังกล่าวมาเป็นพิเศษ
งานแต่ละงานดังกล่าวของ Madry Lab จาก MIT เรียกได้ว่าอ่านสนุกและได้พลิกความเข้าใจเรื่อง AI อย่างมากๆ โดยเพื่อนๆ สามารถอ่านเพิ่มเติมได้ในแหล่งอ้างอิงด้านล่าง และถ้าโอกาสเหมาะสม ทีมงานของเราอาจจะนำงานบางงานมาขยายความเพิ่มเติมเป็นหนึ่งบทความใหญ่ในอนาคตครับผม ^^ สำหรับสัปดาห์นี้ขอฝากไว้เท่านี้ก่อนคร้าบบ

*หมายเหตุ* Topic นี้เป็น Topic ที่ยังเป็นงานวิจัยระดับ Frontier ดังนั้นความเข้าใจต่างๆ อาจเปลี่ยนแปลงได้ในอนาคตครับผม
อ้างอิง - บทความประวัติย่อของ Deep Learning : https://thaikeras.com/2018/rise-of-dl/
- บล็อกของ Madry Lab ที่ MIT เขียนเล่าเรื่อง Adversarial Examples และเกี่ยวกับ Robust Model ที่ทนต่อ Adversarial Noise รวมทั้งเล่างานวิจัยล่าสุดทั้งสามงาน ที่กล่าวในบทความนี้ http://gradientscience.org นอกจากนี้ยังมีลิงก์ไปงานวิจัยอื่นๆ ที่สำคัญตั้งแต่ปี 2014 เป็นต้นมา
- บล็อกของ Google AI เกี่ยวกับ Adversarial Examples และลิงก์ไปยังแหล่งอ้างอิงอื่นๆ https://ai.googleblog.com/2018/09/introducing-unrestricted-adversarial.html
- ตัวอย่างงาน GAN ที่น่าสนใจ https://thaikeras.com/community/%e0%b8%84%e0%b8%b8%e0%b8%a2%e0%b8%aa%e0%b8%b1%e0%b8%9e%e0%b9%80%e0%b8%9e%e0%b9%80%e0%b8%ab%e0%b8%a3%e0%b8%b0/9-gan/
ทำความเข้าใจสิ่งที่ AI ทำนายด้วย Grad-CAM และ Workshop ตรวจสอบเบาหวานในดวงตา - ภาคจบ
บทเรียนแรกๆ ของโมเดล AI และเป็นสิ่งที่เราใช้งานบ่อยที่สุดคือ การ Classification หรือ “การจำแนกประเภทข้อมูล” เช่นในปัญหา “ตรวจสอบเบาหวานในดวงตา” (ดูลิงก์อ้างอิงด้านล่าง) เราต้องการให้ระบบของเราจำแนกอาการป่วยของดวงตาว่ารุนแรง ”ระดับ” ไหนตั้งแต่ระดับ 0 (ปกติ) ถึง 4 (เสี่ยงตาบอด) ซึ่งก็คือ “การจำแนกประเภท” ของดวงตาเป็น 5 ประเภทนั่นเอง (ประเภท 0, ประเภท 1, …, ประเภท 4)
ในปัญหาจำแนกประเภทของเมฆบนท้องฟ้าที่เราได้แนะนำไปในสัปดาห์ก่อน (ดูลิงก์อ้างอิงด้านล่าง) ก็ทำนองเดียวกันที่เราจำเป็นต้องจำแนกประเภทออกเป็น 4 แบบ (ปลา, ดอกไม้, น้ำตาล และก้อนกรวด)
ปัญหาของ AI คือเรื่องของ "การทำให้มนุษย์เข้าใจผลทำนาย"
สิ่งที่เป็นจุดอ่อนหนึ่งที่โมเดล AI ถูกโจมตีมานานในการใช้งานจริง ก็คือ “เราไม่เข้าใจความหมายของการทำนาย” เช่น เวลาระบบ AI ทำนายว่า “ดวงตานี้มีสิทธิที่จะตาบอด” เราจะเชื่อมั่นได้มากแค่ไหน? ถึงแม้นจะผ่านการฝึกสอนบนรูปดวงตานับหมื่นรูป แต่ถ้าปราศจากคำอธิบายเพิ่มเติม ระบบที่ให้คำทำนายดังกล่าวก็อาจจะนำไปใช้จริงได้ลำบาก
เพื่อแก้จุดอ่อนดังกล่าวทีมวิจัยจาก Georgia Institute of Technology จึงได้คิดงานวิจัยที่มีชื่อว่า Grad-CAM ขึ้นมาเพื่อ visualize และทำความเข้าใจในสิ่งที่โมเดลทำนาย (ดู http://gradcam.cloudcv.org/ )

Grad-CAM คืออะไร?
สาระสำคัญของ Grad-CAM ก็คือการ Visualize สิ่งที่โมเดลเห็น เช่นในปัญหาตรวจเบาหวานในดวงตาด้วย Heatmap โดยเราจะสามารถเห็นได้ชัดๆ เลยว่าที่โมเดลทำนายว่าดวงตาเป็นอันตรายนั้น โมเดลพิจารณาจากจุดไหนในดวงตา มองแผลได้ถูกต้องหรือเปล่า ซึ่งจะเป็นการแบ่งเบาภาระแพทย์ได้อย่างมาก
วันนี้ ทีมงานเราจึงนำบทความรวมทั้งตัวอย่างโค้ด Grad-CAM ที่ทีมงานเขียนขึ้นในปัญหาตรวจสอบเบาหวานในดวงตามาเป็น Workshop ที่เพื่อนๆ สามารถทดลองใช้งาน เขียน และเรียนรู้ได้ด้วยตัวเองโดยไม่มีค่าใช้จ่ายบน Kaggle kernel เช่นเคยครับ บทความนี้จะพิเศษหน่อยตรงที่เป็นบทความเดียวกับที่ผู้เขียนได้แชร์ให้กับผู้เข้าแข่งขัน Kaggle คนอื่นๆ ทั่วโลกด้วย ดังนั้นจะเป็นภาษาอังกฤษทั้งหมดครับ ถ้าเพื่อนๆ มีจุดไหนไม่เข้าใจก็สามารถสอบถามได้ในโพสต์ข้างล่างหรือในเว็บบอร์ด www.thaikeras.com/ ได้เลยครับ
ในบทความจะเริ่มจากอธิบายหลักการของ Grad-CAM อย่างง่ายๆ ว่ามีการทำงานอย่างไร จากนั้นก็จะเตรียมข้อมูล และโมเดลที่จะใช้ในการทำนาย ซึ่งขั้นตอนการสร้างโมเดลอย่างละเอียดสามารถศึกษาได้จาก Workshop “AI กับงานศิลปะ” (ลิงก์อ้างอิงด้านล่าง)
จากนั้นก็จะสอนวิธีการโค้ด Grad-CAM เพื่อสร้าง Heatmap จากผลทำนายของโมเดลรวมทั้งทดสอบความ Robust ของโมเดลโดยประยุกต์ใช้ Data Augmentation เพื่อบิดรูปให้ผิดเพี้ยนไปและทดสอบว่าโมเดลเรายังเข้าใจบาดแผลในรูปที่บิดไปได้ถูกต้องหรือไม่ เรียกได้ว่า Workshop นี้เป็นการรวมความรู้ทั้งหมดใน Workshop ก่อนๆ ไว้ครบถ้วนเลยครับ ?
ในรูปด้านล่างเราแสดงตัวอย่างของดวงตา 3 ประเภทคือ (1) โมเดลสามารถหาบาดแผลได้อย่างถูกต้อง (2) โมเดลทำนายผล แต่โดยจริงๆ แล้วไม่เจอบาดแผลที่สำคัญ และ (3) โมเดลตรวจเจอบาดแผลบางจุด แต่ไม่ครบทุกจุดในดวงตา ซึ่งในการสร้างโมเดลที่ดี เราต้องพยายามฝึกสอนจนมั่นใจว่าจะไม่เกิดกรณีที่ (2) และ (3) ขึ้นครับ
ถ้าเพื่อนๆ พร้อมแล้วสามารถเริ่มต้นศึกษาและทดลองทำ workshop ด้วยตนเองได้ที่นี่เลยครับผม 🙂
https://www.kaggle.com/ratthachat/aptos-augmentation-visualize-diabetic-retinopathy
เมื่อศึกษาจากตัวอย่างนี้เพื่อนๆ ที่ทำงาน Classification บน Images ก็จะสามารถนำเป็นแนวทางไปประยุกต์ใช้ได้งานของตนเองได้ครับ
อ้างอิง
1) Official Grad-CAM : http://gradcam.cloudcv.org/
2) Workshop 6 ปัญหาตรวจจับเบาหวานในดวงตาภาค 1 : แนะนำปัญหา - https://www.kaggle.com/ratthachat/workshop-ai-for-eyes-1
3) Workshop 7 ปัญหาตรวจจับเบาหวานในดวงตาภาค 2 : การทำ Data augmentation เพื่อเพิ่มข้อมูลสอนให้โมเดล - https://www.kaggle.com/ratthachat/workshop-augmentation-image-ai-for-eyes-2
4) Workshop 8 AI กับงานศิลปะ : เพื่อนๆ สามารถเรียนรู้วิธีการสร้างและสอนโมเดลสำหรับ Computer Vision ได้ที่นี่ - https://www.kaggle.com/pednoi/deep-learning-imet-collection-2019
5) แนะนำปัญหา Deep Learning บนโจทย์ Climate Change Modeling - https://thaikeras.com/community/%e0%b9%80%e0%b8%81%e0%b8%b5%e0%b9%88%e0%b8%a2%e0%b8%a7%e0%b8%81%e0%b8%b1%e0%b8%9a-kaggle/understanding-clouds-from-satellite-images-%e0%b8%97%e0%b8%b3%e0%b8%99%e0%b8%b2%e0%b8%a2%e0%b8%9b%e0%b8%a3%e0%b8%b0%e0%b9%80%e0%b8%a0%e0%b8%97%e0%b8%82%e0%b8%ad%e0%b8%87%e0%b8%81%e0%b9%89%e0%b8%ad/
6) แนะนำ Kaggle สำหรับเพื่อนๆ ที่ยังไม่รู้จัก - https://thaikeras.com/community/%e0%b9%80%e0%b8%81%e0%b8%b5%e0%b9%88%e0%b8%a2%e0%b8%a7%e0%b8%81%e0%b8%b1%e0%b8%9a-kaggle/
Image Augmentation ภาคต่อ
สวัสดีครับเพื่อนๆ ในบทความก่อนหน้าเราได้พูดเรื่อง Image Augmentation ซึ่งเป็นเทคนิกที่สำคัญมากๆ ที่จะทำให้โมเดล “นำความรู้ไปใช้กับข้อมูลอื่นๆ ในอนาคต”(Generalization)
โดยเพื่อนๆ สามารถเข้าไปฝึกทำ 2Workshops ที่ผ่านมาของ Image Augmentation ภาคปฏิบัติด้วยตัวเองบน GPU Machineโดยไม่มีค่าใช้จ่ายได้จาก “ลิงก์อ้างอิง” ด้านล่างครับ
วันนี้จะขอมาเล่าเพิ่มเติม เทคนิก Image Augmentation ที่ค่อนข้างใหม่ และสามารถนำไปประยุกต์รวมใช้กับเทคนิกใน Workshop ข้างบนได้ทันทีครับ โดย 3 เทคนิกที่ได้รับการยอมรับว่ามีประสิทธิภาพสูงในการทำให้computer เข้าใจรูปภาพมากขึ้นก็คือ Mixup, Cutout และ CutMix (ดูภาพประกอบ)

เทคนิก MixUp
เป็นวิธีการ “รวมภาพ”สองภาพเข้าด้วยกันแบบตรงๆ (เฉลี่ยแบบมี weights) แต่ได้ผลดีเหลือเชื่อ โดยสมมติเรามีภาพ x1 (ภาพหมา)และ x2 (ภาพแมว) ภาพใหม่ที่ได้ก็จะได้ภาพซ้อนกันเบลอๆ ระหว่างสองภาพดังแสดงในรูปแนบ
ภาพใหม่ x3 = w*x1 + (1-w)*x2
และภาพใหม่นี้ก็จะมีความเป็นหมาด้วยความน่าจะเป็น w และเป็นแมว (1-w) เป็นต้น
การเพิ่มตัวอย่างลักษณะนี้ทำให้โมเดล “ทนทาน”หรือ Robust กับตัวอย่างแปลกๆ ที่ไม่เคยพบมาก่อนได้มากขึ้น (โมเดลได้เรียนรู้ “เรื่องแปลก”ขึ้นหนึ่งอย่าง) ซึ่งมีผลทำให้การนำโมเดลไปใช้ในอนาคตมีความแม่นยำมากขึ้นโดยเฉลี่ยด้วยครับ
เพื่อนๆ สามารถดูตัวอย่างการทำ MixUp ภาคปฏิบัติบน Keras (และลองดัดแปลงโค้ด) ได้ที่ Kaggle Notebook นี้เลยครับ
https://www.kaggle.com/mathormad/resnet50-v2-keras-focal-loss-mix-up
โดย Notebook นี้เป็นของเพื่อนชาวเวียดนามของผู้เขียนที่ได้แข่งการแข่งขันการแยกประเภทงานศิลปะด้วยกันมาเมื่อหลายเดือนก่อน และโครงสร้างหลักของโค้ดจะเหมือนกับโค้ดของเรา ดังนั้นจึงถือได้ว่าเป็นภาคเสริมของ Workshop จำแนกภาพงานศิลปะของเราเลยครับ โดยโค้ดส่วน MixUp จะอยู่ในส่วน DataGenerator ครับผม
เทคนิก CutOut(หรือ Random Eraser)
CutOut มีไอเดียที่อาจอธิบายแบบง่ายๆ ว่า “ต่อให้เราตัดหัวสุนัขออกไปจากรูป เราก็อาจจะยังเดาออกว่ารูปที่เห็นคือสุนัข” ในทำนองเดียวกันต่อให้เราตัดชิ้นส่วนอื่นๆ ในภาพออกไป (ไม่ว่าจะเป็นหาง หู ขา หรือองค์ประกอบอื่นในภาพ) เราก็ยังพอที่จะเดาได้ว่าภาพนี้คือสุนัข
ดังนั้นหัวใจของ CutOut จึงเป็นการสุ่มลบภาพบางส่วนออกจากภาพต้นฉบับโดยไม่เปลี่ยนแปลง Labels ซึ่งก็จะทำให้โมเดลมีความทนทานมากขึ้นเช่นกัน เช่นเดิมทีโมเดลอาจจะเน้นจำสุนัขจากหน้าตา แต่พอเราใช้ CutOut Augmentation โมเดลก็จะพยายามต้องจำลักษณะอื่นๆ ของสุนัข เช่น ขา หรือ ขนเข้าไปด้วยโดยเราอาจจะสุ่มลบหลายจุดในรูปเดียวก็ได้
CutOut Augmentation นั้นสามารถ implementได้ง่ายๆ ด้วย Albumentation ซึ่งได้สาธิตให้ดูใน Workshop image augmentation ของเราตามลิงก์ https://thaikeras.com/2019/workshop-image-augmentation-ai-for-eyes-2/
เทคนิก CutMix
CutMix เป็นไอเดียล่าสุดใน3 ไอเดียนี้โดยนำสองไอเดียข้างต้นมารวมกัน โดยแทนที่จะทำแบบ CutOut คือตัดรูปออกไปเฉยๆก็จะสุ่มนำภาพจากรูปที่สองมาใส่แทนภาพในส่วนที่ถูกตัดออกไป เช่นจากรูปในตัวอย่างสุ่มตัดหัวแมวมาใส่รูปสุนัข ซึ่งเจ้า label ของรูปที่ผสมกันแล้วก็จะเป็นสัดส่วนกับพื้นที่ของทั้งสองภาพ (เช่น จากตัวอย่าง เป็นรูปสุนัขและแมวด้วยความน่าจะเป็น 0.6 และ 0.4 ตามลำดับ)
ผู้วิจัยในงาน CutMix ให้เหตุผลว่าในระหว่างการสอนโมเดลนั้นCutOutเสียพื้นที่ในรูปไปฟรีๆ โดยโมเดลไม่ได้เรียนรู้อะไรจากส่วนที่ถูกตัดออกไป ส่วน CutMixนั้นใช้ประโยชน์จากพื้นที่ทุกส่วนจึงมีประสิทธิภาพมากกว่า และยังมี Semantic หรือความหมายของรูปที่ชัดเจนกว่า MixUp ที่ได้รูปเบลออีกด้วย เช่นในรูปที่ 2 เวลาเราดู Grad-CAM (อธิบายในบทความก่อนหน้า)ของ MixUp ระหว่างหมาและแมวสังเกตว่าโมเดลจะไม่สามารถบอกได้ว่าส่วนไหนของรูปที่เป็นสุนัขและส่วนไหนของรูปที่เป็นแมว

เทคนิกนี้ทีมงานยังไม่เคย implement ด้วยตัวเอง แต่สามารถดูตัวอย่างการ implementation ได้ที่นี่: https://github.com/DevBruce/CutMixImageDataGenerator_For_Keras/blob/master/CutMixImageDataGenerator.py
อ้างอิง
(1) paper CutMix https://arxiv.org/pdf/1905.04899.pdf และสามารถย้อนไปดู papers ของ Mixup / Cutout ได้จาก Reference ในเปเปอร์นี้ครับ
(2) บทความ Grad-CAM : https://thaikeras.com/community/main-forum/%e0%b8%a3%e0%b8%a7%e0%b8%a1%e0%b8%9a%e0%b8%97%e0%b8%84%e0%b8%a7%e0%b8%b2%e0%b8%a1-ai-fundamental/#post-221
(3) พื้นฐาน Image Augmentation : https://thaikeras.com/2019/workshop-image-augmentation-ai-for-eyes-2/
(4) Augmentation ภาคปฏิบัติบนปัญหาจำแนกประเภทงานศิลปะระดับโลก : https://thaikeras.com/2019/workshop-ai-for-arts-imet2019/
Deep Double Descent - ปรากฏการณ์หักลงสองรอบของค่า Error ใน Deep Learning Models
 รูปแนบที่ 1 กราฟแสดงความเชื่อของ error curve ในสถิติดั้งเดิม (Classical Statistics - เขียว), curve ที่คาดหวังของนักวิจัย Deep Learning (ส้ม) และ curve ที่เกิดขึ้นจริงจากการทดลอง (น้ำเงิน)
รูปแนบที่ 1 กราฟแสดงความเชื่อของ error curve ในสถิติดั้งเดิม (Classical Statistics - เขียว), curve ที่คาดหวังของนักวิจัย Deep Learning (ส้ม) และ curve ที่เกิดขึ้นจริงจากการทดลอง (น้ำเงิน)
OpenAI ได้ทำการทดลองเกี่ยวกับการฝึกสอนโมเดลขนาดใหญ่บน Deep Learning อาทิเช่น ResNets , Transformers และโมเดลอื่นๆ ในหลายๆ ปัญหาอย่างละเอียด และพบปรากvczฎการณ์ที่น่าประหลาดใจที่ว่า “ค่าความผิดพลาดจะหักลง 2 รอบ” (Double Descent) เสมอ และขัดกับความเชื่อในสถิติดั้งเดิม (ดูรูปแนบที่ 1)
ในทางสถิติดั้งเดิมเชื่อว่าถ้าเราสร้างโมเดลที่ใหญ่มากเกินไป (เส้นเขียว รูปที่ 1) เมื่อ error ถึงจุดต่ำสุดแล้ว ก็จะเกิดปรากฏการณ์ overfit ขึ้น นั่นคือแม้นโมเดลจะอธิบาย training data ได้ดีแค่ไหน แต่พอเอาไปใช้งานจริง (test data) จะทำนาย “ไม่ได้เรื่อง” (ดูรูปแนบที่ 2 - ตัวอย่างการฟิตเส้น Polynomial ดีกรี 3 ด้วย polynomial ดีกรี 20)
 รูปแนบที่ 2 ความเชื่อของสถิติดั้งเดิมที่ว่าถ้าเพิ่มความซับซ้อนของโมเดล ย่ิงมาก จะยิ่งทำนายได้แย่ โดยอ้างอิงจากการฟิตข้อมูลด้วย polynomial degree ที่สูงขึ้นเรื่อยๆ ซึ่งจะเห็นได้ว่าใน polynomial degree 20 แม้จะฟิตข้อมูลได้ทั้งหมดแต่กลับทำนายอะไรไม่ได้เลย
รูปแนบที่ 2 ความเชื่อของสถิติดั้งเดิมที่ว่าถ้าเพิ่มความซับซ้อนของโมเดล ย่ิงมาก จะยิ่งทำนายได้แย่ โดยอ้างอิงจากการฟิตข้อมูลด้วย polynomial degree ที่สูงขึ้นเรื่อยๆ ซึ่งจะเห็นได้ว่าใน polynomial degree 20 แม้จะฟิตข้อมูลได้ทั้งหมดแต่กลับทำนายอะไรไม่ได้เลย
อย่างไรก็ดีตัวอย่าง classic นี้ (พบได้ใน textbooks เกือบทุกเล่ม) ยึดติดว่า polynomial model นั้นเป็นตัวแทนของโมเดลทั้งหมด ซึ่งไม่จริง เพราะมีโมเดล curve อื่นๆ (เช่น smooth spline และอื่นๆ อีกมากมาย) ที่ไม่ overfit แม้นจะเพิ่ม parameters ของโมเดล
กลับมาดูรูปแนบที่ 1 เส้นสีส้ม, ในทางตรงกันข้ามกับสถิติดั้งเดิม ในงานใหม่ๆ ทางด้าน Deep Learning นักวิจัยส่วนใหญ่กลับเชื่อกันว่ายิ่งโมเดลมีขนาดใหญ่มากขึ้น จะยิ่งทำให้ความแม่นยำมากขึ้นเรื่อยๆ (หรือเป็นที่มาของชื่อของ ”Deep” models ที่แปลว่า ยิ่ง ”ลึก” ยิ่งดี หรือ ยิ่ง ”ใหญ่” ยิ่งดี) โดยปรากฏการณ์ที่ Deep Learning เมื่อซับซ้อนมากๆ กลับสามารถทำนายข้อมูลในอนาคตได้แม่นยำขึ้น ก็ได้มีนักวิจัยจาก MIT วิเคราะห์เชิงลึกไว้ ดังที่อ่านได้ในบทความนี้ของ ThaiKeras ครับ http://bit.ly/thaikeras-mini-fundamental
ทว่าในการทดลองอย่างละเอียดของ Open AI กลับพบว่าคำอธิบายทั้งสองนั้นมีส่วนถูกทั้งคู่ โดยกราฟ error จริงๆ (เส้นสีน้ำเงิน) มีลักษณะคล้ายกราฟเส้นสีเขียวของสถิติดั้งเดิมในช่วงแรก และมา “กระดก” กลับเป็นกราฟสีส้มตามความเชื่อของ Deep Learning ในช่วงหลัง
 รูปแนบที่ 3. แสดงโซนที่ test หรือ generalization error curve แสดงพฤติกรรมคล้ายคำอธิบายของสถิติดั้งเดิม (ซ้ายมือ) และโซนที่ test error curve แสดงพฤติกรรมดั่งที่นักวิจัย Deep Learning คาดหวัง (ขวามือ)
รูปแนบที่ 3. แสดงโซนที่ test หรือ generalization error curve แสดงพฤติกรรมคล้ายคำอธิบายของสถิติดั้งเดิม (ซ้ายมือ) และโซนที่ test error curve แสดงพฤติกรรมดั่งที่นักวิจัย Deep Learning คาดหวัง (ขวามือ)
จุดเปลี่ยนโซน (Interpolation Threshold) เกิดขึ้นเมื่อ training error กำลังลดลงอย่างรวดเร็วใกล้จะเป็น 0 นั่นคือโมเดลกำลังจะฟิตข้อมูลรวมทั้ง noise ทั้งหมด
โดยถ้าเราดูให้ละเอียดขึ้น (รูปที่ 3) เราจะพบว่า “จุดเปลี่ยน หรือ จุดกระดก” จะเกิดขึ้นในช่วงที่โมเดลกำลังจะ “เรียนรู้” หรือ “fit” training dat ได้สมบูรณ์พอดี (การทดลองทั้งหมดของ OpenAI ให้กราฟในลักษณะเดียวกัน)
โดย OpenAI เชื่อว่าว่าปรากฏการณ์ Overfit ในช่วงแรก หรือช่วงที่ความซับซ้อนของโมเดลเริ่มเพียงพอสำหรับข้อมูลสอนได้พอดีนั้น จะอ่อนไหวกับ noise (ฟิต noise ไปด้วย) เพราะโมเดลซับซ้อนเพียงพอที่จะฟิตข้อมูลทั้งหมด
ในขณะที่กราฟช่วงหลัง โมเดลมี parameters มากพอ นั่นคือมี subsets ของ parameters มากมายจาก parameters ทั้งหมดที่สามารถฟิตข้อมูลได้ และ “bias หรือ คุณสมบัติ” ของ Optimizer ที่ใช้ในปัจจุบัน (SGD / Adams) นั้น “บังเอิญ” เลือกโมเดลที่สมเหตุผล คือมีความถูกต้องสูงได้พอดี และความบังเอิญนี้เกิดจากอะไรทาง OpenAI เองก็ยังไม่สามารถอธิบายได้
ผู้สนใจสามารถอ่านเพิ่มเติมได้ที่นี่ครับ : https://openai.com/blog/deep-double-descent/
เรื่องย่อของ ฮันส์เจ้าม้าแสนรู้ (ที่อาจเป็นเพื่อนร่วมชะตากรรมของ Deep Learning)
By ThaiKeras and Kaggle (21 Jan 2562)
สวัสดีครับ เมื่อราว 100 กว่าปีที่แล้วมีปรากฎการณ์ฮือฮามากที่ประเทศเยอรมนี นั่นคือมีม้าตัวหนึ่งที่มีความสามารถพิเศษมากมาย อาทิเช่น คิดเลขบวกลบง่ายๆ ได้อย่างถูกต้องและ สามารถแก้ปัญหาเชิงบรรยายที่ซับซ้อนขึ้นมากขึ้นได้ ม้าตัวนี้ถูกเรียกว่า “ฮันส์ม้าแสนรู้” หรือ Clever Hans

เหตุการณ์นี้เริ่มขึ้นในต้น ค.ศ. ที่ 20 ที่ในขณะนั้นชาวยุโรปกำลังสนใจเกี่ยวกับความเฉลียดฉลาดในการเรียนรู้ของสัตว์เป็นอย่างยิ่ง เนื่องจากทฤษฎีวิวัฒนาการของชาลส์ ดาร์วินกำลังเป็นที่โด่งดัง
โดยครูคณิตศาสตร์คนหนึ่งได้พยายามฝึกสอนม้าที่มีชื่อว่าฮันส์ (Hans) ตั้งแต่การบวกลบ ไปจนถึงการแก้เลขเศษส่วน ทำความเข้าใจโน้ตดนตรี และเข้าใจภาษามนุษย์ในระดับง่ายๆ
เช่น ถ้าถามฮันส์ว่า 12+12 เท่ากับเท่าไร ฮันส์ก็จะเคาะเท้า 24 ครั้ง หรือกระทั้่งคำถามที่ว่า "ถ้าวันที่แปดของเดือนเป็นวันอังคาร วันศุกร์ต่อมาจะเป็นวันที่เท่าไร" ฮันส์ก็ยังสามารถเคาะเท้าตอบได้อย่างถูกต้องอีกด้วย!
เจ้าของฮันส์ได้พาฮันส์เดินสายโชว์ไปทั่วประเทศเยอรมนี จนปรากฏการณ์นี้ได้กลายเป็นที่สนใจของนักวิทยาศาสตร์อย่างมากเพื่อที่จะมาพิสูจน์ความจริง จนกระทั่งนักจิตวิทยาที่มีชื่อว่า คาร์ล ชตุมพฟ์ และผู้ช่วยที่ชื่อออสการ์ พุงสท์ได้ตั้งทีมขึ้นมาตรวจสอบอย่างจริงจัง
โดยในปี 1904 ทีมงานไม่สามารถจับผิดเล่ห์กลหรือสิ่งตุกติกใดๆ ได้เลยในการแสดงของฮันส์ แม้ว่าเจ้าของจะไม่ได้เป็นคนถามเอง หรือกระทั่งกรณีเจ้าของไม่ได้ได้อยู่ในกลุ่มคนดูอีกด้วย (นั่นคือเหมือนว่าฮันส์นั้นจะฉลาดอย่างแท้จริง และเจ้าของไมได้เป็นแกงค์ต้มตุ๋นแต่อย่างใด)
หลังจากการสังเกตและทดลองอย่างละเอียดในที่สุดทีมงานก็พบความจริงที่ว่า “ฮันส์จะสามารถตอบคำถามได้อย่างแม่นยำ ก็ต่อเมื่อ ผู้ถามทราบคำตอบเท่านั้น” นั่นคือ
- ถ้าผู้ถามทราบคำตอบ ฮันส์จะตอบถูกถึง 89%
- ถ้าผู้ถามไม่ทราบคำตอบ ฮันส์จะตอบถูกเพียง 6% เท่านั้น
และนอกจากนี้ฮันส์ยังจำเป็นต้องมองเห็นหน้าของผู้ถามอีกด้วย ข้อสังเกตเหล่านี้ทำให้ทีมวิจัยได้ข้อเท็จจริงที่ว่า ฮันส์นั้นเมื่อเคาะเท้าด้วยจำนวนครั้งที่เข้าใกล้คำตอบที่แท้จริงแล้ว จะเริ่มชะลอการเคาะเท้าลง และในขณะเดียวกันผู้ถามเองก็จะแสดงความตื่นเต้นออกทางสีหน้า และม้าอย่างเช่นฮันส์นั้นมีความสามารถในการสังเกตสีหน้าและท่าทางที่เปลี่ยนไปเรื่อยๆ ได้ถูกต้องและเข้าใจสีหน้าที่ตื่นเต้นที่สุดเมื่อเคาะเท้าครบตามคำตอบที่ถูกต้อง โดยที่ผู้ถามเองนั้นไม่ได้มีความตั้งใจที่จะส่งสัญญาณใดๆ เพื่อบอกใบ้กับม้าเลย
!!! นั่นคือ แท้จริงแล้ว ฮันส์ไม่ได้มีความรู้อะไรเลยแม้แต่น้อย!!!
ปรากฏการณ์นี้ สำคัญมากๆ ในการออกแบบการทดลองทางวิทยาศาสตร์ที่จะวัดความสามารถของสัตว์ต่างๆ เพราะถ้าเกิดปรากฏการณ์ทำนองเดียวกับ “Clever Hans” นี้ ข้อสรุปการทดลองทั้งหมดจะใช้ไม่ได้เลย!
........
ย้อนกลับมาที่งาน Deep Learning ก็ได้มีนักวิจัยจากหลายแห่งทั่วโลกสังเกตพบปรากฏการณ์ที่คล้ายๆ กันว่าแท้จริงแล้วโมเดลของเราไม่ได้เข้าใจหัวใจของปัญหาได้อย่างแท้จริง เพียงแต่ค้นพบสถิติที่เกิดขึ้นบ่อยๆ แล้วนำมาตอบคำถามได้ (เหมือนจะ) แม่นยำเท่านั้น แต่เราก็สามารถหาตัวอย่างง่ายๆ ที่ทำให้โมเดลที่เหมือนจะแสนฉลาดเหล่านี้ตอบผิดแบบ “โง่ๆ” ได้ และทำให้ผลการทดลองทั้งหลายที่ว่า Deep Learning มีความฉลาดใกล้มนุษย์ อาจไม่มีความหมายเลยก็เป็นได้!!
ซึ่งก็ได้มีนักวิจัยจากหลายแห่งนำเรื่อง ”ฮันส์ม้าแสนรู้” นี้มาเปรียบเทียบกันอย่างสนุกสนาน (ทำนองเดียวกันกับการมองภาพหมูที่ถูกบิดเล็กน้อย เป็นภาพเครื่องบินดั่งที่เคยเล่าในบทความ http://bit.ly/thaikeras-mini-fundamental )
ในบทความหน้าเราจะมาขอเล่าตัวอย่าง “ฮันส์ม้าแสนรู้” ที่ถูกจับผิดได้สำเร็จในวงการวิจัยฝั่ง NLP (หรือ ความเข้าใจในภาษามนุษย์ของ AI) ซึ่งเพิ่งตีพิมพ์ใน ACL 2019 ซึ่งเป็นหนึ่งในงานประชุมวิชาการที่ใหญ่ที่สุดในวงการ NLP ระดับนานาชาติกันครับ
เพื่อนๆ ที่สนใจปรากฏการณ์ ฮันส์ม้าแสนรู้หรือ Clever Hans สามารถอ่านเพิ่มเติมได้ที่นี่ครับ ;D
ปรากฏการณ์ "Clever Hans" บน NLP (หรือ Deep NLP ไม่ได้เก่งอย่างที่คิด)
By ThaiKeras and Kaggle (28 Jan 2562)
สวัสดีครับเพื่อนๆ วันนี้ขออนุญาตเจาะประเด็นเรื่อง ‘’โมเดล AI กลุ่ม Deep NLP ที่ขึ้นชื่อว่าเก่งกาจด้านภาษาสุดๆ นั้นแท้จริงแล้วเข้าใจ ภาษามนุษย์จริงหรือไม่”
ในตอนที่แล้วเราได้พูดถึงปรากฏการณ์ “Clever Hans” หรือเจ้าม้าแสนรู้ฮันส์ไปแล้ว ( http://bit.ly/thaikeras-nlp-hans) โดยมีหัวใจสำคัญอยู่ที่ว่า เจ้าม้าฮันส์ที่ดูฉลาดมากตอบคำถามได้ทุกเรื่อง โดยที่ไม่มีการตุกติกอะไรทั้งสิ้น แท้จริงแล้วมันไม่ได้มีความรู้อะไรเลย!! ปรากฏการณ์นี้แสดงให้เห็นว่า “การวัดความฉลาด” นั้นยากกว่าที่คิด และไม่สามารถนำผลการทดลอง (ที่ไม่รัดกุม) มาวัดได้เลย
ล่าสุดในงานประชุมวิชาการ ACL 2019 ที่เป็นหนึ่งในงานประชุม NLP (งาน AI เกี่ยวกับการเข้าใจภาษามนุษย์) ที่ดีที่สุดในโลก ก็ได้มีนักวิจัยจากหลายแห่งชำแหละปรากฏการณ์เดียวกันนี้ของโมเดล AI หรือ Deep Learning ฝั่ง NLP ระดับสุดยอดเช่น BERT
(ดูเรื่้อง BERT ได้ที่ http://bit.ly/thaikeras-nlp-transfer ) ว่าแท้จริงโมเดลอัจฉริยะเหล่านี้อาจ “ไม่ได้รู้อะไรเกี่ยวกับภาษามนุษย์” เลย นอกจากมีความเชี่ยวชาญเรื่อง “สถิติ” ของคำต่างๆ เท่านั้น และทำให้นักวิจัยต่างกล่าวว่านี่คือปรากฏการณ์ “Clever Hans Moment ในวงการ NLP” เลยทีเดียว!! (ดูอ้างอิง 1.) เหตุการณ์นี้เป็นอย่างไรลองมาฟังรายละเอียดกันครับ
 รูปที่ 1 ล้อเลียน BERT สุดยอดโมเดล AI ในงานด้าน NLP หรือด้านภาษามนุษย์ ว่าแท้จริงแล้วเปรียบเสมือนฮันส์ คือไม่ได้รู้เรื่องอะไรเกี่ยวกับภาษาอย่างแท้จริงเลย (ภาพจากอ้างอิง 1.)
รูปที่ 1 ล้อเลียน BERT สุดยอดโมเดล AI ในงานด้าน NLP หรือด้านภาษามนุษย์ ว่าแท้จริงแล้วเปรียบเสมือนฮันส์ คือไม่ได้รู้เรื่องอะไรเกี่ยวกับภาษาอย่างแท้จริงเลย (ภาพจากอ้างอิง 1.)
การวัดความฉลาดทางภาษาด้วยการตอบปัญหาทางตรรกะ
เหตุการณ์นี้เริ่มต้นจากการวัดความเข้าใจในภาษามนุษย์ของโมเดล Deep Learning นั้นจะวัดผลจาก Dataset ที่แล็บต่างๆ รวบรวมมาจากแหล่งข้อมูลทั่วโลก โดยตัวอย่าง Dataset หนึ่งที่ได้รับการยอมรับว่า “น่าจะ” วัดความเข้าใจภาษามนุษย์ของ AI ได้ก็คือ Dataset ขนาดใหญ่ที่มีชื่อว่า Multi-Genre Natural Language Inference (MNLI) ที่มหาวิทยาลัยระดับโลกอย่าง New York University เป็นผู้รวบรวมขึ้นมา โดย Dataset นี้จะมุ่งทดสอบปัญหาความเข้าใจ “ตรรกะ” ซึ่งอธิบายได้ดังนี้
กำหนดให้โมเดล AI เช่น BERT (ซึ่งถูกฝึกมาอย่างดี) อ่านประโยคสองประโยค แล้วต้องตอบว่า ”ประโยคที่สองนั้นเกี่ยวข้องกับประโยคแรกหรือไม่” โดยมีคำตอบที่เป็นไปได้สามแบบดังนี้
1. ประโยคสอง “สรุปได้“ จากประโยคแรก — (entailment) ประโยคแรก: The doctor was paid by the actor ประโยคสอง: The actor pays the doctor
2. ประโยคสอง “ขัดแย้ง” กับประโยคแรก — (contradiction) ประโยคแรก: The doctor was paid by the actor ประโยคสอง: The actor does not pay the doctor
3. ประโยคสอง “ไม่เกี่ยว” กับประโยคแรก — (neutral) ประโยคแรก: The doctor was paid by the actor ประโยคสอง: The doctor and the actor have fun together
โดย Dataset MNLI นี้มีขนาดใหญ่ถึง 433,000 คู่ประโยค มาจากหลายแหล่ง และแต่ละประโยค ค่อนข้างมีความหลากหลายและซับซ้อนทางไวยากรณ์กว่าตัวอย่างที่แสดงข้างต้นมาก (ผู้สนใจดูตัวอย่างที่เอกสารอ้างอิง 2. ) ทั้งนี้เพื่อใช้ทดสอบให้แน่ใจว่าโมเดลนั้นเข้าใจภาษาจริงหรือไม่ สมมติฐานก็คือถ้าโมเดลสามารถตอบคำถามในคู่ประโยคที่มีความซับซ้อนระดับนี้ เป็นจำนวนมหาศาลได้ถูกต้องจริง นั่นก็แปลว่า “โมเดลมีความเข้าใจภาษาอย่างแท้จริง”
แต่สมมติฐานนี้เป็นจริงหรือไม่?
ความทรงพลังของสถิติและจุดอ่อนของ Datasets
นักวิจัยสองกลุ่มจาก John Hopkins และ Taiwan ได้ทำการทดลองอย่างละเอียดและพบว่า “สถิติ” ของกลุ่มคำนั้นมีพลังมากกว่าที่เราคิด โดยจุดอ่อนของ MNLI ก็คือ ถึงแม้ว่าข้อมูลจะมีความหลากหลายและซับซ้อนสูง Datasets ชุดนี้ก็ยังมีจุดร่วมบางอย่างอยู่ที่ทำให้โมเดลสามารถสร้าง “กลวิธีในการเดาคำตอบ” (Heuristic) ได้
 รูปที่ 2 ตัวอย่างวิธีการเดา (heuristic) ที่ทีมวิจัยพบว่า BERT นำมาใช้
รูปที่ 2 ตัวอย่างวิธีการเดา (heuristic) ที่ทีมวิจัยพบว่า BERT นำมาใช้
ทีมวิจัยพบว่าแท้จริงแล้ว โมเดล “ค้นพบ” ถึง “วิธีการเดาอย่างง่ายๆ” (Heuristic) ดังปรากฏในรูปที่ 2 ตัวอย่างเช่น
ถ้าประโยคที่ 2 มี substring ที่สอดคล้องกับประโยคที่ 1 มาก ให้ตอบว่า ประโยคที่ 2 “สรุปได้“ (entailment) จากประโยคที่ 1 (ดูตัวอย่างในคอลัมภ์สุดท้ายของรูปที่ 2.)
วิธีการเดานี้แม้ไม่ถูกต้อง 100% แต่ก็ให้ผลลัพธ์ถูกต้องราวๆ 80% บน MNLI ซึ่งเพียงพอในการจะ “หลอก” มนุษย์อย่างพวกเราว่า ”AI นั้นเก่งจริง!!”
อย่างน้อยก็เก่งเหมือนเจ้าม้าฮันส์ที่สามารถคิดวิธี “เดา” เหล่านี้ได้เอง โดยวิธีการเดาเหล่านี้สามารถใช้ได้กับข้อมูลทั่วๆ ไปจริง แต่สามารถตอบผิดได้ 100% ถ้าผู้ถามทราบวิธีการเดาเหล่านี้
ทำไม Datasets ถึงมีจุดอ่อนง่ายๆ แบบนี้?
ถึงแม้ว่าทีม NYU ซึ่งเป็นผู้รวบรวม Dataset MNLI ได้พยายามรวบรวมรูปประโยคจากหลายแหล่งในโลก ทว่าก็ยังเป็นรูปประโยคที่พบได้ทั่วไป และ “ไม่ได้” ถูกออกแบบมาเพื่อ “ดักวิธีการเดาง่ายๆ“ เหล่านี้ ซึ่งแสดงให้เห็นว่าการออกแบบการทดลอง และ Datasets มีความสำคัญมาก
เจ้าม้า BERT ผู้ซึ่งถูกจับได้ และตอบผิดเกือบ 100% ซึ่งทีมวิจัยได้ทดสอบด้วยการออกแบบและสร้าง Dataset NLI อีกชุดที่เรียกว่า HANS (ล้อเลียนเจ้าม้าฮันส์) ซึ่งย่อมาจาก “Heuristic Analysis for NLI System” โดยจงใจสร้างประโยคที่ 2 ให้ขัดแย้งกับประโยคที่ 1 ถึงแม้ประโยคที่ 2 จะเป็น substring ของประโยคแรกก็ตาม ดูตัวอย่างประโยคในคอลัมภ์สุดท้ายของรูปที่ 2 ครับ
และพบว่าเมื่อให้เจ้าม้า BERT ที่มีความแม่นยำสูงใน MNLI มาทดสอบใน Dataset HANS นี้ (ซึ่งมนุษย์เราตอบได้ถูกเกือบ 100%) ปรากฏว่าเจ้าม้า BERT จะตอบผิดเกือบ 100% เลยครับ!!!
แสดงว่า BERT ที่ปรากฏตามงานวิจัยที่ผ่านมาว่าเข้าใจภาษามนุษย์อย่างดีนั้น ไม่ได้เข้าใจภาษามนุษย์เลย!! (แบบเดียวกับม้าฮันส์เป้ะ)
ความสำคัญของการทำนาย “ข้อมูลที่ไม่ค่อยพบเจอ” หลายคนอาจสงสัยว่า "แล้วความรู้ทางสถิติที่สอดคล้องจากข้อมูลมหาศาลมันไม่ดีตรงไหน มันยิ่งทำให้แม่นยำกับโลกความเป็นจริงไม่ใช่เหรอ"? คำตอบคือ ใช่ครับ มันอาจจะแม่นยำกับข้อมูล "ปกติ" แต่มันสามารถทำงานผิดพลาดได้ 100% (พูดภาษาบ้านๆ คือ ผิดแบบน่าอับอาย) ได้ตลอดเวลาถ้าเจอข้อมูลที่ "ไม่ค่อยได้พบเจอ" (หรือ “ไม่เคยเจอ”)
จุดนี้หลายคนอาจสงสัยต่อว่า เราต้องใส่ใจข้อมูลที่ “ไม่ค่อยเจอ” ด้วยเหรอ?
ขอตอบให้ชัดครับว่า เรา “จำเป็น” ต้องใส่ใจกับข้อมูลที่ “ไม่ปกติ” เหล่านี้ถ้าโมเดลของเราถูกนำไปใช้ในงานที่เกี่ยวข้องกับ "ความปลอดภัย" ต่างๆ
ลองจินตนาการถึงโลกอนาคตที่ AI ทำงานแทนมนุษย์เป็นเรื่องปกติ และเรายังไม่สามารถแก้จุดอ่อนนี้ได้ ย่อมเปิดโอกาสให้ผู้ไม่ประสงค์ดี หรือผู้ก่อการร้ายต่างๆ สามารถเล่นงานจุดอ่อนนี้ของ AI และทำให้ระบบความปลอดภัยต่างๆ ล้มเหลวได้ไม่เป็นท่าทันที ปัญหานี้จึงสำคัญมากๆ ในเหตุการณ์ที่ไม่ปกติแต่รุนแรงมากเหล่านี้ครับ
สำหรับผู้สนใจสามารถอ่านรายละเอียดเพิ่มเติมได้ในงานวิจัยฉบับเต็มในเอกสารอ้างอิง 3 และ 4 ครับ หรืออ่านบทความเพิ่มเติมในบทความเอกสารอ้างอิง 1. ครับ 😀
UPDATE กค. 2020 นักวิจัยได้คิดค้นวิธี syntactic data augmentation เพื่อให้เจ้าม้า Bert มีความเข้าใจ syntax ที่หลากหลายมากขึ้น และทำให้ไม่หลงกลข้อมูลใน Dataset HANS นี้ง่ายๆ โดยหลังจาก augment ไปแล้ว ความแม่นยำของ Bert บน Dataset HANS นั้นเพิ่มขึ้นหลายเท่าตัว ผู้สนใจดูเพิ่มได้ใน https://arxiv.org/pdf/2004.11999.pdf
เอกสารอ้างอิง
1. https://thegradient.pub/nlps-clever-hans-moment-has-arrived/
2. Dataset MNLI : https://www.nyu.edu/projects/bowman/multinli/
3. Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference : https://www.aclweb.org/anthology/P19-1334.pdf
4. Probing Neural Network Comprehension of Natural Language Arguments : https://www.aclweb.org/anthology/P19-1459.pdf
