

Feb 2022, update 5 โมเดลที่แข่งกันเป็นที่สุดในปี 2022 ฝั่ง computer vision ในโพสต์ด้านล่างครับ
----
รู้จัก EfficientNet โมเดลที่แข็งแกร่งที่สุดในปฐพีบน Computer Vision 2019
เพื่อนๆ ที่รู้ประวัติของ Deep Learning นั้น ทราบดีว่างานพลิกโลกเหล่านี้มีต้นกำเนิดจาก AlexNet บน ที่เอาชนะคู่แข่งบนปัญหา Computer Vision ได้ขาดลอย (ดูประวัติฉบับเต็มได้ที่่นี่ครับ https://thaikeras.com/2018/rise-of-dl/)
ถัดจาก AlexNet ก็มีโมเดล “Deep Learning” ชื่อดังกำเนิดอีกมากมาย ที่ดังมากๆ ก็คือ Inception จากทีม Google, ResNet จากทีม Microsoft หรือ ResNeXt จากทีม Facebook เป็นต้น ใน Kaggle เองโมเดลเหล่านี้ก็ยังเป็น “กระดูกสันหลังสำคัญของแชมเปี้ยน” ของแต่ละการแข่งขัน
ขึ้นชื่อว่า “Deep” Model เพื่อนๆ อาจพอเดากันได้ว่าโมเดลที่คิดค้นออกมาช่วงหลังๆ มักจะมีความลึกขึ้นเรื่อยๆ จากเดิม Network ความยาว 7 ชั้นบน AlexNet มาเป็น หลายสิบชั้นบน Inception และหลักร้อยชั้นบน ResNet
ปรากฏการณ์เหล่านี้ทำให้บางช่วงเวลา นักวิจัย วิศวกรทั้งหลายเข้าใจไปว่า “ความลึก” คือกุญแจสำคัญของความสำเร็จของ Neural Networks
อย่างไรก็ดีมีนักวิจัยบางกลุ่มพบว่า เราอาจไม่ต้องเพิ่มความสามารถของโมเดลจากการเพิ่ม “ความลึกเท่านั้น” แต่เรายังสามารถ “เพิ่มความกว้าง” (จำนวน convolution filters) ของแต่ละชั้นก็ทำให้โมเดลมีประสิทธิภาพที่เพิ่มขึ้นได้ จึงคิดค้นโมเดลอย่าง “Wide ResNet” ( https://arxiv.org/pdf/1605.07146v3.pdf) ที่เน้นความกว้างแทนความยาวและมีประสิทธิภาพใกล้เคียงกับ ResNet ได้
มาถึงจุดนี้เพื่อนๆ อาจเริ่มสงสัยว่า Deep Learning Model ควรจะกว้างหรือควรจะยาวกันแน่? และถ้าความกว้างคือคำตอบ เราควรจะเปลี่ยนเป็น Wide Learning แทน Deep Learning ไหม (อันนี้ผมคิดเอง :D)
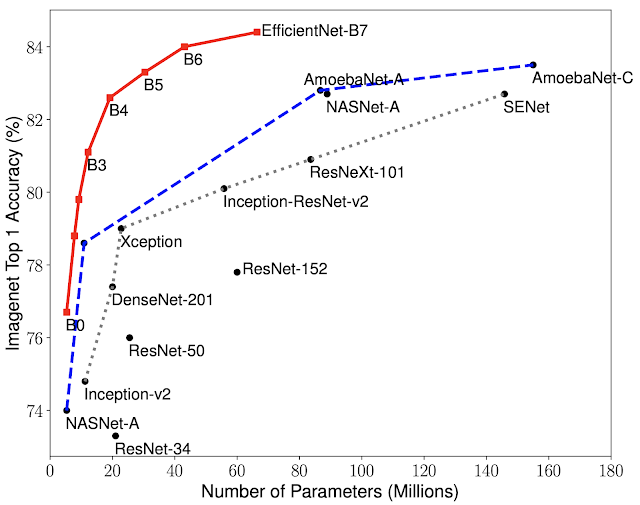
เข้าเรื่อง EfficientNet กันสักทีครับ นั่นคือ สดๆ ร้อนๆ ในเดือนพฤษภาคมที่ผ่านมา ปี 2019 ของเรานี่เอง ทางทีม Google ก็ได้ส่งโมเดลที่ปฏิวัติวงการ Image Recognition ซึ่งก็คือ “EfficientNet” นี่เองครับ โดย EfficientNet นั้นจะมีตั้งขนาดเล็กคือ B0 B1 ไปจนถึงโมเดลขนาดยักษ์นั่นคือ B6 B7 ซึ่งชนะโมเดลอื่นๆ ทั้งหมดในปัจจุบันอย่างขาดกระจุย (ดูภาพประกอบครับ)
ก่อนอื่น EfficientNet มีที่มาอย่างไร ??
EfficientNet ( https://arxiv.org/abs/1905.11946) นั้นถูกคิดโดย 1 ในนักวิจัยระดับสุดยอดของวงการในทีม Google ที่มีนามว่า Quoc V. Le (ถ้าใครทราบว่าอ่านออกเสียงชื่อพี่เค้าอย่างไร รบกวนบอกแอดมินด้วยครับ 55) ที่ขบคิดปัญหาที่เราเกริ่นข้างต้นว่า โมเดลที่มีประสิทธิภาพจริงๆ ควรจะ “Deep” หรือ “Wide” กันแน่? ในที่สุด Q. Le และทีมงานอีกคนที่ชื่อ Mingxing Tan ก็ถึงบางอ้อครับ “โมเดลที่ดีที่สุดควรจะทั้ง Deep และ Wide ในระดับที่เหมาะสม” และเปลี่ยนมุมมองใหม่ว่า
(1) เอา computational resource เป็นตัวตั้งต้น
(2) ควรค่อยๆ scale ทั้งความ Deep และ Wide ไปพร้อมๆ กันตามทรัพยากรที่มี ถ้ามีน้อยก็ Deep และ Wide น้อยๆ (ตั้งชื่อว่า B0) และถ้าทรัพยากรเยอะก็เพิ่มสเกล Deep และ Wide ไปเรื่อยๆ (B1 B2 … B7)
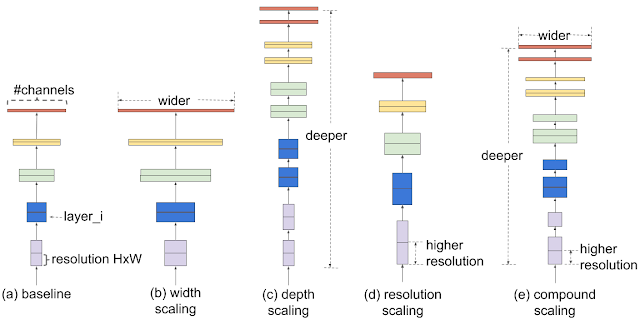
โดยทีมงานทั้งสองได้ประยุกต์ใช้ AutoML หรือสุดยอดงานของ Google อีกหนึ่งงาน ที่ช่วยพิจารณาการเพิ่มสเกลที่ประสิทธิภาพสูงสุด โดย Google ถึงกับเคลมว่าในทรัพยากรที่จำกัดบางช่วงนั้น EfficientNet นั้นทรงพลัง (เร็วและเล็ก) กว่า state-of-the-art ปัจจุบันนับ 10 เท่า!! จากกราฟเทียบประสิทธิภาพเพื่อนๆ จะเห็นว่า B0-B7 โมเดลให้ความแม่นยำกว่าโมเดลในไซส์เดียวกันมากๆ อาทิเช่น โมเดล B2 ซึ่งมี Parameters ราว 10 ล้านให้ความแม่นยำกว่า SOTA ไซส์เดียวกันคือ NASNet-A หลายช่วงตัว และให้ความแม่นยำสูสีกับ Inception-ResNetV2 ที่มี parameters มากกว่า 6 เท่า!!
(เพื่อนๆ ที่อยากทราบว่า state-of-the-art คืออะไร อ่านได้ที่นี่ครับ : https://thaikeras.com/community/main-forum/%E0%B8%84%E0%B9%89%E0%B8%99%E0%B8%87%E0%B8%B2%E0%B8%99%E0%B8%9E%E0%B8%A3%E0%B9%89%E0%B8%AD%E0%B8%A1%E0%B9%82%E0%B8%84%E0%B9%89%E0%B8%94%E0%B8%97%E0%B8%B5%E0%B9%88%E0%B8%94%E0%B8%B5%E0%B8%97%E0%B8%B5/ )
บทความนี้เราเพียงแนะนำให้เพื่อนๆ รู้จัก EfficientNet ระดับผิวเท่านั้น อดใจรออีกไม่นาน ทีมงานจะพาเพื่อนๆ ลองใช้งาน Keras EfficientNet กันจริงๆ ในภาคต่อของปัญหา “ตรวจจับเบาหวานในดวงตา” ครับ ซึ่ง EfficientNet นี้นับว่าเป็นกุญแจสำคัญของผู้เข้าแข่งขันระดับท้อปหลายๆ ทีมบนการแข่งขันนี้ทีเดียวครับ
ถ้าเห็นว่าบทความมีประโยชน์ พิจารณา Like & Share เพื่อเป็นกำลังใจให้ทีมงานหน่อยนะคร้าบ
สำหรับการใช้ EfficientNet บน Keras นั้นสามารถ copy จากสุดยอด Github นี้ได้เลยครับ
https://github.com/qubvel/efficientnet
โดย Github นี้ล่าสุดปี 2020 ได้ update weight ที่เรียกว่า ‘noisy-students’ ซึ่งมีความแม่นยำยิ่งกว่า ‘imagenet’ ไปอีกขั้นหนึ่งด้วยครับ ตัวอย่างการติดตั้งและใช้งาน EfficientNet ดังกล่าวภาคปฏิบัติสามารถดูได้จาก Workshop iMet2019 ซึ่งเป็นการใช้ EfficientNet ในการระบุ tags สิ่งของนับแสนชิ้นในพิพิธภัณฑ์ระดับโลกครับ
https://www.kaggle.com/pednoi/deep-learning-imet-collection-2019
ไดอะแกรมความเหนือชั้นของ Noisy Student weights

รายละเอียดเพิ่มเติม
บทความเจาะลึก Transformers ล้ำๆ จาก Huggingface team
ThaiKeras and Kaggle 11 พย. 2563
สวัสดีครับเพื่อนๆ เชื่อว่าทุกคนที่ทำงาน data science หรือ machine learning ด้านภาษา หรือข้อมูลมีลำดับ (sequential data) ย่อมรู้จักเป็นอย่างดีกับโมเดล Transformers ซึ่งปัจจุบันเป็น "มาตรฐานที่ดีที่สุด" ของงานกลุ่มนี้ โดยโมเดลที่ดีที่สุดในสามปีหลังต่างก็เป็น "สมาชิก" ในตระกูลนี้ทั้งสิ้น
นอกจากนี้เพื่อนๆ ย่อมรู้จักทีม Huggingface ซึ่งเป็นเจ้าของ open source library ของโมเดล Transformers ต่างๆ ที่ครบถ้วนมากที่สุด และใช้งานง่ายที่สุด และครอบคลุมทั้ง Tensorflow-keras และ Pytorch
อย่างไรก็ดีนอกจากผลงานโมเดลแล้ว ทีม Huggingface ยังได้แชร์ความรู้ผ่านบทความหรือโน้ตบุคมากมายอีกด้วย วันนี้อยากแนะนำบทความที่จะเป็นพื้นฐานสำคัญๆ ที่จะทำให้เราเข้าใจโมเดลที่พัฒนาล่าสุดและดีที่สุดในปัจจุบันครับ
Transformer-based Encoder-Decoder Models
โดย Patrick von Platen อ่านที่นี่ --> https://huggingface.co/blog/encoder-decoder
โมเดล Transformers ดั้งเดิมนั้นประกอบไปด้วย สองบล็อกใหญ่ๆ คือบล็อก Encoder ซึ่งทำหน้าที่เปลี่ยนข้อมูล (หรือเรียกเท่ห์ๆ ว่า "เข้ารหัส") อาทิเช่น ประโยคในภาษาต่างๆ ให้เป็นเวกเตอร์ทางคณิตศาสตร์
บล็อกที่สองคือ Decoder ก็จะทำหน้าที่ "ถอดรหัส" เวกเตอร์ทางคณิตศาสตร์ให้กลับมาเป็นข้อความที่เราต้องการครับ
หลักการเข้ารหัสและถอดรหัสหรือ Encoder-Decoder นี้ สามารถใช้กับงานทางด้านภาษามากมาย อาทิเช่น
- แปลภาษา เช่น เข้ารหัสภาษาอังกฤษ และถอดรหัสออกเป็นภาษาไทย
- ย่อความ เช่น เข้ารหัสบทความต้นฉบับ (ยาวๆ) และถอดรหัสออกมาเฉพาะข้อความที่สำคัญจริงๆ
- ตอบคำถาม เช่น เข้ารหัสประโยคคำถาม และถอดรหัสออกมาเป็นประโยคคำตอบ (ในกรณีนี้โมเดลต้องมี "ความรู้" ในตัว หรือสามารถเข้าถึงความรู้ที่ถูกต้องและ "เข้ารหัส" ความรู้ร่วมกับคำถามได้ )
ซึ่งโมเดลชื่อดังระดับเทพต่างๆ ที่เราเห็นในเพจของ Huggingface https://huggingface.co/transformers/model_summary.html นั้น เช่น T5, Bart, MarianMT, Pegasus หรือ ProphetNet ล้วนแต่มี architecture พื้นฐานแบบเดียวกันทั้งสิ้น ดังนั้นถ้าเพื่อนๆ เข้าใจพื้นฐานของ Encoder-Decoder นี้อย่างดีแล้วก็จะทำให้เพื่อนๆ เข้าใจโมเดลที่คิดขึ้นมาใหม่ได้อย่างไม่ยาก
ในบทความนี่้ Patrick จะอธิบาย Transformers อย่างละเอียดมากๆ (มากที่สุดเท่าที่ผมเคยอ่านบล็อกเกี่ยวกับ Transformers มาเลยครับ 😀 )
- ความเป็นมา เจ้า Transformers ซึ่งได้รับแรงบันดาลใจจาก RNN นั้นถูกคิดค้นมาได้อย่างไร ?
- อธิบาย "ภาพใหญ่" หรือ flow ของ Encoder-Decoder ผ่านกรอบของ "ทฤษฎีความน่าจะเป็น"
- เจาะลึกสมการฝั่ง Encoder
- เจาะลึกสมการฝั่ง Decoder
Patrick เจ้าของบทความนี้เป็นผู้ implement โมดูลสำคัญๆ บน Huggingface หลายชิ้น เช่น T5, Sampling-based Decoding และ Beam-Search Decoding ทำให้ตกผลึกออกมาเป็นบทความนี้ครับ
ผมมั่นใจว่าถ้าเพื่อนๆ อ่านจบบทความนี้ รวมทั้งทำความเข้าใจโค้ด tutorial transformer ของ official tensorflow ( https://www.tensorflow.org/tutorials/text/transformer ) เพื่อนๆ จะเข้าใจ Transformers อย่างลึกซึ้งแน่นอน ซึ่งทำให้เข้าใจแก่นสำคัญของโมเดลล่าสุดต่างๆ อีกด้วย
นอกจากนี้ อ่านเพิ่มเติมบทความภาษาไทยได้ที่
https://thaikeras.com/2018/transfer-learning-nlp/
http://bit.ly/thaikeras-medium-transformer
FixEfficientNet -- เพิ่มประสิทธิภาพของ EfficientNet ขึ้นไปอีกขั้น จากทีม FB-AI
สรุปย่อๆ (มาก) 22 Transformers ที่สำคัญบน Huggingface
ThaiKeras and Kaggle 15 พย. 2563

สวัสดีครับเพื่อนๆ ในบทความก่อนเราได้แชร์บทความเจาะลึก Transformers ของ Patrick จากทีม Huggingface ซึ่งเป็น library ของ Transformers ที่มีโมเดลให้เลือกใช้มากที่สุด (วันที่เขียนบทความนี้มีทั้งหมดราว 40 โมเดล)
อย่างไรก็ดีการมีตัวเลือกมากเกินไปบางครั้ง ทำให้ผู้ใช้ใหม่ๆ สับสนได้เหมือนกันว่าโมเดลใดเหมาะกับปัญหาแบบไหน และแตกต่างกันอย่างไร วันนี้ทีม ThaiKeras ได้ลองแยกประเภทและสรุปย่อ (มากๆ) โมเดลเฉพาะที่เรารู้จักคร่าวๆ ไว้ --- เราก็ไม่รู้จักทุกโมเดลเหมือนกันครับ แหะๆ
อย่างที่โพสต์ก่อนหน้าได้เกริ่นไป ( https://bit.ly/thaikeras-understanding-nlp ) เจ้า Transformers นั้นดั้งเดิมแล้วประกอบไปด้วยองค์ประกอบสองส่วนคือ ส่วนของ Encoder และส่วนของ Decoder โดยบล็อก Encoder ซึ่งทำหน้าที่เปลี่ยนข้อมูล (หรือเรียกเท่ห์ๆ ว่า "เข้ารหัส") อาทิเช่น ประโยคในภาษาต่างๆ ให้เป็นเวกเตอร์ทางคณิตศาสตร์ ส่วน Decoder ก็จะทำหน้าที่ "ถอดรหัส" เวกเตอร์ทางคณิตศาสตร์ให้กลับมาเป็นข้อความที่เราต้องการ
ทว่าในบางปัญหานั้น การมีแค่ Encoder หรือแค่ Decoder เพยงอย่างเดียวก็จะเหมาะสมกว่า ซึ่งทำให้เราอาจแบ่งประเภทของ Transformers ได้เป็น 4 ประเภทครับ
- Encoder-only (ในเพจ Huggingface เรียก Autoencoder models)
- Decoder-only (ในเพจ Huggingface เรียก Autoregressive models)
- Encoder-Decoder (หรือ Sequence-to-sequence models)
- Multi-modal Encoder-Decoder
โดย
- เจ้า Transformers ที่มี Encoder เพียงอย่างเดียวนั้นจะเหมาะกับปัญหาพื้นฐานพวก classification, regression, token classification และ reading comprehension (closed-domain Q&A -- ดูรายละเอียดที่ ตอนที่ 4 ใน https://bit.ly/thaikeras-understanding-nlp ) ตัวอย่างเช่น Bert, Roberta, XLM-Roberta, Longformer, DPR, etc.
2. กลุ่มที่มี Decoder เพียงอย่างเดียวก็จะเหมาะกับการ "สร้างเรื่องราวแบบอิสระ" (story generation) เช่นตระกูล GPT, GPT-2 และ GPT-3 รวมทั้ง BertGeneration กลุ่มนี้ไม่ได้สร้าง output จาก input ที่เจาะจงโดยตรง (เพราะไม่มี encoder module) จึงเหมาะกับการสร้างเรื่องราวที่เป็น "อิสระ" และมีความสร้างสรรค์
3. กลุ่ม Encoder-Decoder ซึ่งสร้าง output จาก input ก็จะเหมาะกับปัญหา แปลภาษา (translation) ตอบคำถามแบบทั่วไป (free-form Q&A) หรือย่อความ (Summarization) ถึงแม้ว่า output ของโมเดลกลุ่มนี้จะขึ้นกับ input โดยตรง แต่ output ก็จะมีความ "อิสระ" หรือ "สร้างสรรค์" ได้ เช่นในปัญหา free-form Q&A เมื่อเจอคำถามประเภท "ทำไม?" หรือ "อย่างไร?" โมเดลจะสามารถอธิบายและให้แง่คิดเกี่ยวกับคำถามได้อย่างอิสระ ตัวอย่างของโมเดล เช่น T5, Bart และ RAG
4. กลุ่ม Multi-modal encoder-decoder เป็นกลุ่มพิเศษซึ่งเพิ่งเริ่มเข้ามาใน Huggingface ปี 2020 นี่เอง นั่นคือ input นอกจากจะเป็น sequential data ได้แล้วยังรับ input พวก image ได้ด้วย เช่นปัญหา image captioning ที่โมเดลสามารถ "เล่าเรื่องราว" จากรูปภาพได้เป็นต้น (ดูตัวอย่างเก่าๆ ของเราที่ https://www.kaggle.com/ratthachat/flickr-image-captioning-tpu-tf2-glove ) โมเดลชื่อ LXMert เป็นตัวอย่างในกลุ่มนี้
ข้างล่างนี้จะเราจะลองสรุปย่อๆ ในแต่ละโมเดล ซึ่งในเพจของแต่ละโมเดลบน Huggingface จะมีลิงก์ไปยัง original paper ทุกโมเดลครับผม
https://huggingface.co/transformers/model_doc/bert.html (เปลี่ยนชื่อจาก bert เป็นโมเดลที่ต้องการ)
เนื่องจากเป็นสรุปสั้นๆ อาจเน้นศัพท์เทคนิคเพื่อความกระชับ ขออ้างอิงความหมายไปยังบทความฉบับก่อนๆ นะครับ https://bit.ly/thaikeras-understanding-nlp ส่วนขนาดของ pretrained models ต่างๆ จะมีสรุปที่หน้านี้ครับ https://huggingface.co/transformers/pretrained_models.html
โมเดลกลุ่ม Encoder-only
1.1 Bert : โมเดล Encoder-only แรกและเป็นต้นแบบของโมเดลอื่นๆ ทุกตัวในกลุ่มนี้ ทีม Bert เป็นผู้ริเริ่มแนวคิด pretrained บน unlabled data (self-supervised) แบบ masked language modeling (MLM) ซึ่งเมื่อ pretrain สำเร็จแล้ว สามารถไป finetune ต่อที่ปัญหาประเภท "เลือกคำตอบ" (ที่เป็นมาตรฐานการวัดสำคัญในขณะนั้น) เช่น classification, token classfication ใดๆ ก็ได้และได้ผลลัพธ์ที่ดีที่สุด (ในขณะนั้น) ทันที นับเป็นการปฏิวัติวงการ NLP ที่ถูกเรียกว่า "ImageNet moment of NLP" ล้อไปกับปรากฏการณ์ pretrained บน ImageNet ที่ทำให้งาน Computer Vision ก้าวกระโดดเมื่อปี 2012 นั่นเอง โดยเราเคยเล่าไว้ที่นี่ครับ https://thaikeras.com/2018/rise-of-dl/
โดย Bert แบ่งเป็น Bert-large และ Bert-base (330 ล้านพารามิเตอร์ และ 110 ล้านพารามิเตอร์) โดยโมเดลใหญ่จะให้ความผลที่ดีกว่าแทบจะเสมอในทางปฏิบัติ
1.2 Albert : เป็นโมเดลจากทีม Google ที่ออกแบบให้มีการแชร์พารามิเตอร์กันให้มากที่สุด ทำให้ประหยัดพื้นที่ storage มากกว่า Bert มาก อย่างไรก็ดียังมีความซับซ้อน (deep หรือประกอบไปด้วยนิวรอนหลาย layers) ในระดับเดียวกับ Bert ทำให้ความต้องการ memory และความเร็วไม่ต่างจาก Bert มากนัก เนื่องจาก Albert ประหยัดเนื้อที่เก็บมากกว่า Bert, ทำให้ทีมวิจัยทดลองขยายขนาดความซับซ้อนนอกจาก Albert-base และ Albert-large แล้วยังมี Albert-xlarge และ Albert-xxlarge
1.3 DistilBert : เป็น Bert จากทีม Huggingface ขนาดเล็กราวๆ ครึ่งนึงของ Bert-base และ pretrain ด้วยเทคนิก distillation นั่นคือเทรนบน soft-labels ของ Bert-large ซึ่งทำให้มีความแม่นยำน้อยกว่า Bert-base ไม่มาก (เช่น 10-15% จากการทดลอง) แม้จะมีขนาดเล็กกว่ามาก โมเดลนี้ถูกพัฒนามาราว 2 ปีก่อน ซึ่งปัจจุบันมี MobileBert ซึ่งดีกว่ามาก
1.4 MobileBert : Bert ขนาดจิ๋ว ในปี 2020 ที่ออกแบบโดยทีม Google เอง ซึ่งมีขนาดเล็กกว่า Bert-base เพียง 25% ของ bert-base และเร็วกว่า bert-base ถึง 5 เท่า แต่มีประสิทธิภาพโดยรวมใกล้เคียง Bert-base
1.5 SqueezeBert : เป็น Bert ขนาดจิ๋ว คู่แข่งของ MobileBert ซึ่งมีความเร็วและประสิทธิภาพใกล้เคียงกัน
1.6 Electra : เป็น Bert จากทีม Google ที่ออกแบบวิธีการ pretrain ให้พัฒนาจาก MLM ของ Bert ดั้งเดิม ทำให้เมื่อนำไป finetune จะมีความแม่นยำมากกว่า Bert (เล็กน้อย)
1.7 Roberta เป็น bert จากทีม Facebook ซึ่งได้ optimize การ pretrain MLM ของ bert ดั้งเดิม รวมทั้งเพิ่ม pretrained dataset ให้ใหญ่กว่าเดิมมาก ทำให้ได้ผลลัพธ์ดีกว่า Bert
1.8 Longformer : พัฒนาต่อจาก Roberta โดยทีม AI2 ได้มีการปรับแนวคิด attention mechanism ใหม่ (อธิบายในบทความแนะนำ transformers ของ Patrick ในตอนที่แล้ว) ให้เน้น attend local vector เป็นหล้ก จึงทำให้รองรับ input sequence ได้ยาวกว่า Bert และ Roberta มาก นั่นคือรองรับได้ถึง 4096 tokens ในขณะที่ bert และ roberta มาตรฐานอยู่ที่ 512 tokens
1.9 XLM-Roberta : พัฒนาต่อจาก Roberta โดย pretrain จาก dataset ถึง 100 ภาษาพร้อมกันทำให้เข้าใจภาษาเกือบทุกภาษาทั่วโลก ซึ่ง ThaiKeras เคยนำเสนอ workshop เกี่ยวกับ XLM-Roberta ไว้ที่นี่ครับ https://bit.ly/thaikeras-kaggle-xlmr
1.10 DPR : เป็นโมเดลเกือบล่าสุดจาก Facebook โดยพัฒนาให้มี "ความรู้" สำหรับปัญหา open-book Q&A โดยเฉพาะ เมื่อเจอคำถามใดๆ โดยใช้เทคนิคดึงข้อมูลในวิกิพีเดียที่เกี่ยวข้องขึ้นมาอ่าน และ "คัดลอก" ประโยคที่คาดว่าจะเป็นคำตอบจากบทความที่อ่านมาตอบคำถาม
โมเดล DPR เวอร์ชั่น Tensorflow-Keras บน Huggingface นั้นเขียนโดยทีม ThaiKeras ของเราเองครับ! ซึ่งเราภูมิใจมาก และจะขออนุญาตขยายความในบทความหน้าครับผม
.
โมเดลกลุ่ม Decoder-only
2.1 GPT-2 : โมเดลในตำนานของทีม OpenAI ที่เป็นผู้ริเริ่มการใช้ Decoder-only architecture โดยใช้การ pretraining ที่เรียกว่า "language model" หรือการ "เขียนบทความเลียนแบบ" จากบทความต่างๆ ใน trainnig data โดย pretraining dataset ของ GPT-2 นั้นเป็น article มหาศาลแทบทุกประเภทบน internet ครับ
เพื่อนๆ สามารถทดลองแต่งเรื่องราวสร้างสรรค์ด้วย GPT-2 บน workshop ของเราที่นี่ครับ https://bit.ly/thaikeras-kaggle-gpt2thai
ใน huggingface นั้น มี pretrained models ให้เลือกหลายขนาดคือ 'gpt2' (ขนาดเล็กสุด 117ล้าน พารามิเตอร์), 'gpt2-medium' (ขนาด 345 ล้านพารามิเตอร์) 'gpt2-large' (ขนาด 774 ล้านพารามิเตอร์) 'gpt2-xl' (ขนาด 1.5 พันล้านพารามิเตอร์)
อนึ่งแม้ทีม OpenAI จะสร้างโมเดล GPT-3 ขึ้นมาแล้วในปี 2020 ทว่าไม่ได้ opensource ทำให้เราไม่สามารถใช้งานได้ใน Huggingface ครับ
2.2 Diablo GPT : คือ GPT-2 ที่ถูกนำมา pretrain ใหม่โดยทีม Microsoft บน chat logs จำนวนมหาศาล ทำให้ Diablo GPT นั้นสามารถพูดคุยตอบโต้ได้คล้ายกับ Chatbot (แทนที่จะแต่งเรื่องไปเรื่อยๆ เหมือน GPT-2 ปกติ)
2.3 Ctrl : เป็นโมเดลขนาด 1.6 พันล้านพารามิเตอร์ใกล้เคียง gpt2-xl จากทีม Salesforce โดยได้ออกแบบให้ training data มี tag ต่างๆ กัน เช่น tag "wikipedia", "horror" หรือ "legal" เป็นต้น ดังนั้นในตอนที่เราสร้างสรรค์เรื่องราวเช่นเดียวกับ gpt-2 เราจะสามารถควบคุมเนื้อเรื่องให้สอดคล้องกับ tag ที่กำหนดได้
.
โมเดลกลุ่ม Encoder-Decoder
ดั่งที่เกริ่นในบทความตอนที่แล้ว Encoder-Decoder เหล่านี้สถาปัตยกรรมไม่ต่างกันมาก จุดที่แตกต่างจะเป็น pretrained data ของแต่ละตัวครับผม
3.1 MarianMT : โดยทีม HelsinkiNLP เป็น transformers ดั้งเดิมเพื่องาน "แปลภาษา" โดยเฉพาะ โดยมี pretrained models บนคู่ภาษามากกว่า 1,000 คู่รวมทั้งคู่ english-thai, french-thai
3.2 T5 : โดยทีม Google , ถ้าไม่นับ GPT-3 เจ้า T5 นับว่าเป็นโมเดลที่ใหญ่และดังทีสุดในปี 2020, เนื่องจากเป็นโมเดลแรกที่ทำ benchmark มาตรฐาน SuperGLUE ที่ยากที่สุดของปัญหา "เลือกคำตอบ" ได้ทัดเทียมมนุษย์ (รายละเอียดในตอนพิเศษใน https://bit.ly/thaikeras-understanding-nlp ) และเจ้า pretrained weights นอกจากสามารถใช้ตอบคำถามต่างๆ superGLUE แล้วยังสามารถ "ย่อบทความ" ได้ในตัวโดยไม่ต้อง finetune ใดๆ จึงนับว่าสารพัดประโยชน์มากๆ
T5 มี pretrained weights หลายขนาดเช่นกัน คือ t5-small, t5-base, t5-large, t5-3B (3พันล้านพารามิเตอร์) และ t5-11B (1.1 หมื่นล้านพารามิเตอร์) ใหญ่มากจนคนธรรมดาอย่างเราใช้ไม่ได้ :p เพราะต้องการเครื่อง spec สูงมากๆ
3.3 Bart : ของทีม Facebook ซึ่งเป็นคู่แข่งของ T5 (ใน size ใกล้เคียงกัน) โดย Bart นั้นมีการ pretrain บน unsupervised data และงาน "ย่อความ" คล้ายๆ T5 แต่ไม่มี pretrained บน superGLue
3.4 mBart : โดยทีม Facebook เช่นกัน ขยายความสามารถของ Bart เพื่อแปลภาษาหลายคู่ภาษา
3.5 BlenderBot : เป็น Chatbot ที่น่าจะดีที่สุดที่มี Opensource ผลงานจากทีม Facebook เช่นเดิม โดยมี structure เช่นเดียวกับ Bart แต่ขยายให้ใหญ่ขึ้น โดยตัวที่ใหญ่ที่สุดใน Huggingface มีขนาด 3พันล้านพารามิเตอร์
3.6 RAG : โมเดลล่าสุดจาก Facebook ที่รวมความสามารถของ Bart และ DPR เข้าด้วยกัน ซึ่งเป็นหนึ่งในไม่กี่โมเดลในปัจจุบันที่ตอบปัญหา Free-form Open-Domain Question-Answering ได้ นั่นคือตอบคำถามอะไรก็ได้ โดยไม่ต้องใบ้คำตอบใดๆ เลยแม้แต่น้อย เนื่องจากโมเดลจะไปค้นวิกิพีเดียมาตอบเอง และสามารถตอบได้อย่างอิสระด้วยความสามารถของ Bart (ไม่ได้ก้อปปี้คำตอบจากบทความมาเหมือน DPR) โมเดลนี้เป็นโมเดลที่ผมสนใจเป็นการส่วนตัวที่สุด และ ThaiKeras กำลังเขียนเวอร์ชัน Tensorflow-Keras ร่วมกับ Huggingface อยู่ครับ
3.7 Pegasus : อีกหนึ่งโมเดลจากทีม google ออกแบบ unsupervised pretraining task ใหม่ (อีกแล้ว) และปัจจุบันเป็น 1 ในโมเดลที่ทำงานด้าน "ย่อความ" ได้ดีที่สุด โดยมีความสามารถใกล้เคียงกับ T5 ตัวที่ใหญ่ที่สุดทั้งที่โมเดลมีขนาดเล็กกว่ามาก
3.8 ProphetNet : โมเดลจากทีม Microsoft ที่ออกแบบ unsupervised pretraining task ให้ทำนาย tokens ในอนาคตแบบ N-Gram พร้อมกัน และ Microsoft report ว่าโมเดลนี้เมื่อนำไป finetune ให้ผลลัพธ์ที่ดีมากๆ ในหลาย dataset
โมเดลกลุ่ม Multi-modal
4.1 LXMert : เป็นโมเดลแรกใน Huggingface ที่ฝั่ง Encoder รับ input ที่เป็นรูปภาพและภาษาได้พร้อมกัน ซึ่งทำให้ทำงานที่เชื่อมระหว่างสองโดเมนนี้ได้ เช่น อธิบายรูปภาพ (image captioning) และตอบคำถามจากภาพ (visual question answering) เป็นต้น
ในอนาคตถ้าผมได้มีโอกาสทดลองใช้และศึกษาเพิ่มเติม ก็จะมาอัพเดตบทความนี้เรื่อยๆ เพื่อให้ทันสมัยมากขึ้นครับ สำหรับบทความหน้าเราจะมาเจาะและทดลองใช้โมเดลที่สามารถอ่านวิกิพีเดียเพื่อตอบคำถาม ที่ชื่อว่า DPR (1.10) กันครับ
