

ว่าด้วยเรื่อง Keras Tokenizer และ Sequence Representation
Tokenizer
การเตรียม data ยังไม่จบแค่นี้ครับ ทั้งนี้ที่ผ่านมาเราได้ทำ "คำ" ต่างๆ ในกระทู้ให้มีความเรียบร้อยขึ้นแล้วก็จริง แต่เนื่องจาก Computer หรือ AI นั้น ณ ตอนที่เราเริ่มสร้างมันครั้งแรก มันจะไม่รู้จักภาษา และไม่สามารถทำความเข้าใจ "คำ" ต่างๆ ได้โดยตรงครับ
ดังนั้น วิธีการที่ง่ายที่สุด ก็คือการ map ให้คำแต่ละคำแทนด้วยตัวเลข อาทิเช่น "a" แทนด้วย 1, "the" แทนด้วย 2 และ "restaurant" แทนด้วย 35486 เป็นต้น ซึ่งเราสามารถทำได้โดยการสร้าง dictionary ที่ map จากเซ็ตของคำศัพท์ทั้งหมด ไปยังตัวเลขตั้งแต่ 1 ถึง N_VOCABS (โดย N_VOCABS แทนจำนวนคำศัพท์ที่ต้องการ)
ทั้งนี้ N อาจมีค่าน้อยกว่าคำศัพท์ทั้งหมดจริงๆ ก็ได้ เนื่องจากคำศัพท์บางคำที่ปรากฎเพียงแค่ครั้งเดียว เช่น "spectroscopy" ก็จะไม่มีผลต่อความเข้าใจในการคัดกรองกระทู้ที่ insincere ครับ (นั่นคือ N_VOCABS เป็น hyper-parameters ที่เราต้องทดลองเพื่อหาค่าที่เหมาะสมที่สุด ในการใช้งานจริง)
โชคดีมากครับที่ (a) กระบวนการตัดคำ (b) เรียงคำศัพท์ที่ปรากฏบ่อยที่สุดจากมากไปน้อย สร้าง (c) dictionary ตามจำนวนศัพท์ N คำที่เราต้องการ และ (d) เปลี่ยนประโยคให้เป็น sequnce ของ ตัวเลขที่ map ตามคำในประโยคเรียบร้อย
ทั้งหมดนี้เราสามารถทำได้ง่ายๆ โดย keras ครับ ซึ่ง keras จะมี object ที่ชื่อ Tokenizer ที่จะทำหน้าที่ทั้งหมดนี้ให้เราเสร็จสมบูรณ์ด้วยโค้ดไม่กี่บรรทัด

ขอบคุณรูปสวยๆ จาก mlwhiz.com เช่นเคยครับ
<code># ตัวแปร train_X คือแทนข้อมูลสอน test_X คือข้อมูลทดสอบ # รายละเอียดฉบับเต็ม รอชมใน workshop นะครับ from keras.preprocessing.text import Tokenizer tokenizer = Tokenizer(num_words= N_VOCABS) tokenizer.fit_on_texts(list(train_X)) train_X = tokenizer.texts_to_sequences(train_X) test_X = tokenizer.texts_to_sequences(test_X)</code>Sequence Padding
ขั้นตอนสุดท้ายถัดจาก Tokenize ก็คือขั้นตอนที่เรียกว่า sequence padding ครับ เนื่องจากกระทู้แต่ละกระทู้มีความยาวไม่เท่ากัน อาทิเช่น
"Am I a good person ?" <-- มีความยาว 6 คำ
"Let me be straight . I do not understand why man usually think of a woman like this ?" <-- มีความยาว 19 คำ
และบางกระทู้อาจยาวได้ถึง 100 คำ (แม้จะ preprocess แล้ว)
เพื่อให้การเรียนรู้และตีความของ AI ทำได้ง่าย เราจะกำหนดให้ทุกประโยคมีความยาวที่เท่ากัน โดยการกำหนดตัวแปร MAX_LEN โดยประโยคที่มีความยาวมากกว่า MAX_LEN เราก็จะตัดคำที่เกินทิ้งไป ส่วนประโยคที่มีความยาวน้อยกว่า MAX_LEN เราก็จะใส่ "คำพิเศษ" ที่ชื่อว่า "PAD" จนเต็มความยาว MAX_LEN ครับ
จากตัวอย่างข้างบนถ้าเรากำหนด MAX_LEN = 15 เราก็จะได้ประโยค
"Am I a good person ? PAD PAD PAD PAD PAD PAD PAD PAD PAD" <-- มีความยาว 15 = MAX_LEN คำ
"Let me be straight . I do not understand why man usually think of a" <-- มีความยาว 15 = MAX_LEN คำ หรือเราจะเลือกตัดคำส่วนหน้าก็ได้ เช่น
" . I do not understand why man usually think of a woman like this ?" <-- มีความยาว 15 คำ เช่นกัน เลือกในได้ option ของ keras tokenizer
ซึ่งแท้จริงแล้ว keras จะแปลงประโยคข้างบนเป็น list of numbers อย่างที่กล่าวข้างบนโดยอัตโนมัติ และ PAD จะถูกแทนด้วย 0 เช่น
"Am I a good person ? PAD PAD PAD PAD PAD PAD PAD PAD PAD" -->
[15, 2, 1, 49, 532, 98, 0, 0, 0, 0, 0, 0, 0, 0, 0] เป็นต้น ซึ่ง list of numbers นี้สามารถนำไปใช้ได้ใน Deep Learning architectures ได้แล้วครับ
from keras.preprocessing.sequence import pad_sequences train_X = pad_sequences(train_X, maxlen=maxlen) test_X = pad_sequences(test_X, maxlen=maxlen)

@aek ขอบคุณคุณ Aek มากคร้าบ พอดีที่ผ่านมาเป็นโค้งสุดท้ายของการแข่งขัน (ซึ่ง ณ วันที่โพสต์นี้วันสุดท้ายแล้ว) ซึ่งดุเดือดมากๆ และพวกเราก็ต้องนั่งแก้บั้ก และก็สั่งรันกันอย่างเข้มข้น เลยทำให้แผนการเขียนบทความต่างๆ เลื่อนไปเล็กน้อย ถ้าคุณ Aek มีคำแนะนำหรือสนใจเรื่องอะไรเป็นพิเศษก็โพสต์ได้เลยนะครับผม หรือหาอะไรคุยเล่นก็ได้ครับ 😀
ปล. 6/2/2019 ผมอัพเดตกระทู้ข้างบนหลายเรื่องเพื่อให้ปัญหามีความชัดเจนขึ้นครับ 🙂
ผ่านกันมาหลายโพสต์ เราก็ยังไม่ได้เริ่มต้นออกแบบ machine learning architecture ที่จะใช้ทำนายกระทู้กันเสียทีนะครับ ทั้งนี้เป็นเพราะว่า "ขั้นตอนการทำความเข้าใจปัญหา" และ "ขั้นตอนจัดการข้อมูลให้เรียบร้อย" นั้นมีความสำคัญเป็นอย่างยิ่งในการทำงานด้าน AI / Data Science (ซึ่งเรื่องนี้มักไม่ค่อยถูกเน้นในคอร์ส Machine Learning และทุกคนจะเข้าใจเอง ตอนต้องมาจัดการปัญหาจริง)
What do we have here?
ทบทวนกันหน่อยนะครับ ทั้งหมดที่เราทำกันมา ในโพสต์ก่อนหน้าคือ การเปลี่ยนประโยคภาษาอังกฤษ เช่น
"Am I a good person??" ให้เป็น Object ทางคณิตศาสตร์ของประโยคนั้นๆ ครับ โดยแท้จริงแล้ว Object ที่ว่านี้ก็คือ Matrix นั่นเอง (เนื่องจากเราเอา Vectors ขนาด EMBED_DIM ตามจำนวน MAX_LEN คำมาต่อเรียงกัน จึงเกิดเป็น Matrix) โดยมีกระบวนการดังนี้ครับ
1) PreProcessing / Cleaning "Am I a good person??" --> "am i a good person ? ?"
2) Tokenizing "am i a good person ? ?" --> [15, 2, 1, 49, 532, 98, 98]
3) Padding [15, 2, 1, 49, 532, 98, 98] --> [15, 2, 1, 49, 532, 98, 98, 0, 0, 0, 0, 0, 0, 0, 0] (ยาว = MAX_LEN = 15)
4) Word Embeding [15, 2, 1, 49, 532, 98, 98, 0, 0, 0, 0, 0, 0, 0, 0] --> [x_1, x_2, x_3, ..., x_15]
ซึ่งก็คือ การทำการโยงคำแต่ละคำ ไปเป็น vectors ขนาด EMB_DIM = 300 เช่น คำแรกมี index ที่ 15 (ซึ่งก็คือคำว่า am) จะถูกนำไป map กับ dictionary ของ pretrained word vectors ที่ Kaggle/Quora เตรียมไว้ให้อีกที
15 --> x_1 โดย x_1 เป็น vector ใน Euclidean space ขนาด 300 (EMB_DIM) มิติ
2 --> x_2
1 --> x_3 เป็นต้นครับ
ณ ตอนนี้ input ของเราจึงถูกเปลี่ยนจากประโยคภาษาอังกฤษ ไปเป็น Matrix [x_1, x_2, x_3, ..., x_15] ซึ่งมีขนาด MAX_LEN * EMB_DIM หรือ 15x300 เรียบร้อยแล้วครับ

รูปสวยๆ จาก Mlwhiz.com เช่นเคยครับ ในรูปนี้ใช้ GloVe เป็น pretrained word vectors แทนใช้สัญลักษณ์ d แทน EMB_DIM
โดย Machine Learning หรือ Neural Network Models ทั่วไปนั้นสามารถทำงานกับ Matrix (หรือ Set of Vectors) ได้โดยตรง เนื่องจากแต่ละตัวอย่างสอน (ประโยค) ตอนนี้ถูกแทนด้วย "set ของ features จำนวนคงที่" เราจึงสามารถนำความรู้ Machine Learning ในตำราเรียนมาใช้ได้ ณ จุดนี้ครับ
จำนวน features ในที่นี่นั้นเราอาจออกแบบได้หลายแบบเช่น 300x15 = 4500 features หรือจำนำ word vectors ทั้ง 15 คำมาเฉลี่ยกันก็จะได้ 300 มิติหรือ 300 features ครับ ก่อนหน้าที่ Deep Learning จะเป็นมาตรฐานสากลนั้น เรามักจะเลือกใช้การเตรียม features ในวิธีหลังครับนั่นคือ 300 features เพื่อให้การทำงานของ Models ของเรามีประสิทธิภาพทั้งในแง่หน่วยความจำและเวลาที่ใช้ในการฝึกสอน
ตัวอย่าง models ที่สามารถใช้ได้
- Support Vector Machine
- Logistic Regression
- Multi-layer Neural Networks
- Classification Trees
- K-Nearest Neighbors
- Boosting Machine
อย่างไรก็ดีวิธีการ "เฉลี่ย word vectors" ที่กล่าวมาทั้งหมดนั้นมี "จุดอ่อน" ที่สำคัญมากๆ ครับ นั่นคือถ้านำมาใช้ตรงๆ แล้ว models machine learning ทั้งหลายจะมอง Input เป็น "Set of Vectors" แทนที่จะเป็น "Sequence of Vectors"
ต่างกันอย่างไรเหรอครับ? ถ้าเรามองประโยคเป็น "set ของ คำ" นั่นก็หมายถึงเราจะไม่เอาข้อมูลเรื่อง "ลำดับ" มาใช้ เช่น "Am I a good boy" ก็จะไม่มีความแตกต่างจากประโยคเช่น "I good boy Am a" (ซึ่งอ่านไม่รู้เรื่อง) หรือบางทีความหมายอาจจะสลับกัน เช่น "Martins hates Peters" ก็จะกลายเป็นมีความหมายเดียวกับ "Peters hates Martins" ดังนั้นการนำ word vectors ในประโยคมาเฉลี่ยกันก็จะสูญเสีย information ที่สำคัญของประโยคไป
ดังนั้นในการทำความเข้าใจ "ประโยค" อย่างแท้จริงนั้น เราต้องเอาข้อมูลในส่วนของ "ลำดับ" มาใช้ด้วยครับจะได้ตีความถูกอย่างแท้จริง อย่างไรก็ดีการนำ word vectors ทั้งประโยคมาร้อยต่อกันตรงๆ แล้วมองเป็น features นั้น (เช่น 300 x 15 = 4500 features ตามตัวอย่างข้างบน) นั้นมักจะไม่มีประสิทธิภาพอย่างมากทั้งในแง่หน่วยความจำและเวลาที่ต้องใช้ในการสอนของแต่ละโมเดล โดยในทางปฏิบัตินั้น MAX_LEN อาจจะเท่ากับ 60-100
และกลุ่มหนึ่งของ Deep Learning Models ที่ได้รับการยอมรับอย่างกว้างขวางและถูกออกแบบเรื่องการนำข้อมูลประเภท "ลำดับ" มาใช้อย่างมีประสิทธิภาพก็คือ กลุ่มที่เรียกว่า "Recurrent Neural Networks" (RNNs) ครับ โดยมี 2 Models ในกลุ่มนี้ที่โด่งดังที่สุดคือ Long-short-term Memory Networks (LSTMs) และ Gated Recurrent Units (GRUs) ซึ่งเราสามารถเลือกใช้ LSTMs หรือ GRUs ก็ได้
(แท้จริงแล้ว ในการแข่งขันนี้ เพื่อให้ได้คะแนนสูงสุด เราต้องนำ LSTMs / GRUs มาผสมกันต่อขึ้นไปอีกเพื่อหา Architectures ที่ดีทีสุด แต่เรื่องนี้เป็นปลีกย่อย ซึ่งไม่จำเป็นในแง่ของการออกแบบ Solution หรือ Conceptual Design ครับ)
Train และ Test
ไอเดียของ "Recurrent" Neural Networks (RNNs)
RNNs จัดการข้อมูลประเภท sequential หรือ "มีลำดับ" เช่น ลำดับของคำในประโยคได้อย่างไร ?
ไอเดียหลักของ RNNs คือสร้าง States ไว้เป็นหน่วยความจำ และอ่านข้อมูลทีละคำ ทีละคำ เพื่ออัพเดตข้อมูลล่าสุดใน states (ไอเดียเหมือนกับ finite state machines ที่เพื่อนๆ เอกคอมพิวเตอร์คุ้นเคย หรือ dynamic systems ที่เพื่อนๆ สายวิศวกรรมหรือสายวิทยาศาสตร์จะรู้จักกันดี)
เนื่องจาก RNNs อ่านข้อมูลทีละคำ (จากซ้ายไปขวา หรือจากขวาไปซ้ายก็ได้) ทำให้ RNNs สามารถแยกแยะได้ว่าประโยค อย่าง "Peters hates Martins" จะไม่เหมือนกับ "Martins hates Peters" เนื่องจากหลังจากอ่านคำแรกแล้ว RNNs จะสามารถเก็บ states ของ "ประธาน" ในประโยคได้ว่าเป็น Peters หรือ Martins และแยกแยะจากคำนามตัวที่สองที่เจอในภายหลังได้
นอกจากนี้การอ่านข้อมูล "ทีละคำ" ทำให้แต่ละครั้งที่อ่าน RNNs ก็จะจัดการกับข้อมูลจำนวน EMB_DIM features เท่านั้น (เวกเตอร์ 300มิติ ในที่นี่) ซึ่งมีประสิทธิภาพมากกว่าการจัดการข้อมูลทีเดียว EMB_DIM x MAX_LEN (เวกเตอร์ 4500มิติ ในตัวอย่างนี้) เป็นอย่างมาก
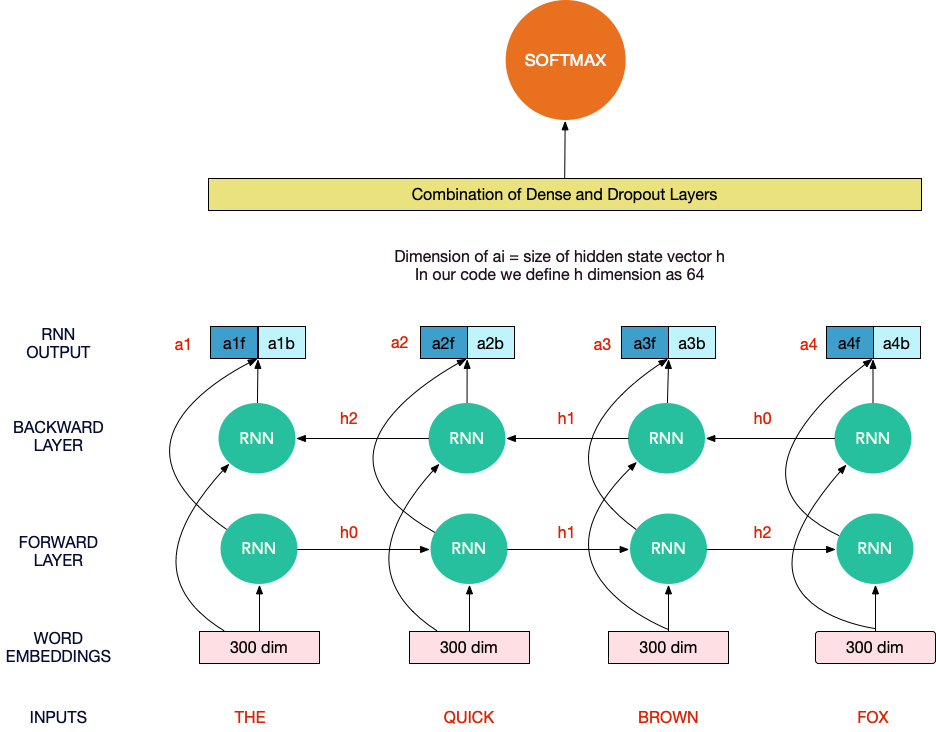
ref: mlwhiz.com
Deep Learning Architecture พื้นฐานที่ใช้คัดกรองกระทู้ insincere
ถ้าเพื่อนๆ เข้าใจไอเดีย RNN Architectures พื้นฐาน รวมทั้งภาพใหญ่เกี่ยวกับปัญหา ข้อมูล และ word embedding พื้นฐาน ก็จะสามารถเข้าใจภาพรวม architectures พื้นฐานที่เราใช้จัดการปัญหานี้ได้ไม่ยากดั่งแสดงในรูปข้างบนครับ
ใน architecture พื้นฐาน โดยขั้นตอนหลักๆ จะแบ่งออกเป็นสามขั้นตอน ซึ่งประกอบไปด้วย layers หลักๆ 3 กลุ่มครับ
ในภาพรวมเรามองระบบเป็น BlackBox คือ
Input ("ลำดับของคำ" ที่ร้อยเรียงเป็นเนื้อหาในกระทู้) --> BlackBox --> Output (1 (กระทู้ไม่ดี) หรือ 0 (กระทู้ดี))
และภายใน BlackBox ก็จะเป็นดังนี้ครับ
Word Embedding Layer --> (bi-directional) RNN layers --> Fully Connected with Softmax layer
1) Word Embedding Layer ก็จะเป็น layer ที่รับ sequence of indices ของคำที่ได้จาก Keras Tokenizer เพื่อ transform ไปเป็น sequence of word vectors ที่เราได้ pretrianed กันไว้แล้ว
Output จาก Layer นี้จึงเป็น Tensor 3 มิติ นั่นคือ (มิติของประโยคในตัวอย่างสอน, มิติของตำแหน่งในประโยค, มิติของ word vectors) ในตัวอย่างการใช้จริง เรามีตัวอย่างราว 1.3 ล้านตัวอย่าง, แต่ละประโยคเราจำกัดความยาวที่ราวๆ 70 คำ และ word vectors เป็นเวกเตอร์ที่มีขนาด 300มิติ ดังนั้น Tensor 3มิติ ของเราจึงมีขนาด (1.3Million, 70, 300) เป็นต้น
2) RNN Layer : เป็น LSTM หรือ GRU ที่รับ Tensor 3D ข้างต้นเข้ามา และส่ง Tensor 3D กลับออกไป โดยคงขนาด 2มิติแรกของ Tensor เอาไว้ และ มิติที่ 3 เราสามารถกำหนดเองได้ว่าอยากให้ information ที่ผ่านการประมวลผลและเรียนรู้โดย LSTM แล้วเป็นเวกเตอร์ในกี่มิติ (ผู้เข้าแข่งขันส่วนใหญ่เห็นตรงกันว่า มิติที่ 3 ควรมีขนาดราวๆ 64-128 มิติ เพื่อไม่ให้ overfit และประมวลผลได้ทันในเวลา 2 ชม.)
3) Information Summation and Softmax (Prediction) Layer : Tensor 3D ที่ได้จาก LSTM นั้นยังแบ่งเป็นคำๆ (ตามมิติที่ 2 ของ Tensor) ณ จุดนี้ ที่เราต้องการประมวลผลข้อมูลเพื่อทำนายในขั้นสุดท้าย เราจึงจะสรุปข้อมูลใมิติที่ 2 ของ Tensor และยุบมิตินี้ทิ้ง ดังนั้น Output สุดท้ายของ Layer นี้จึงเป็น Tensor 2D นั่นคือ (มิติของประโยคในตัวอย่างสอน, มิติของคำทำนายว่าเป็นประโยค insincere หรือไม่) โดยมิิติที่ 2 ใน Tensor2D นี้ก็จะเป็นค่าความน่าจะเป็นที่ softmax layer ทำนายว่า แต่ละตัวอย่างประโยคที่สอนนั้นมีความน่าจะเป็นที่จะ insincere มากหรือน้อยอย่างไร
ทำไมถึงยังเรียก architecter ข้างบนว่า "พื้นฐาน" ?
เพราะเวลาใช้งานจริง เราจำเป็นต้องดัดแปลง ปรับปรุง optimize ให้ผลการทำนายถูกต้องมากที่สุด บน architecture ี้อาทิเช่น
- ใช้ multiple word embedding layers : แทนที่จะเลือกใช้ pretrained word embedding ชุดใดชุดหนึ่ง เราก็พยามใช้ทั้ง 4 ชุดตามที่โจทย์ให้มาเลย โดยอาจจะนำ word vectors ที่ได้จาก pretrained ทั้ง 4 ชุดมาเฉลี่ยกัน เป็นต้น ทั้งนี้เพื่อ maximize pretrained knowledge ให้มากที่สุด
- ใช้ multi-layers RNNs นั่นคือ แทนที่จะใช้ (bidirectional) RNN เพียง layer เดียว เราก็สามารถซ้อน RNNs เข้าไปได้อีกหลายชั้นเพื่อ transform ประโยคของเราให้อยู่ในรูปที่เหมาะสมต่อการทำนายมากที่สุด
- regularizing layers : เป็น layers ที่ช่วยในการไม่ให้ network ของเรา overfit นั่นคือไม่ให้ "จำ" สิ่งที่เรียนทื่อๆ โดยไม่ได้สร้างเป็นความรู้ เช่น dropout, spatial dropout layers เป็นต้น
- Specialized layers : อาทิเช่น Attention layer, capsule layer ก็มีผู้เข้าแข่งขันหลายๆ คนพบว่าช่วยในการทำนายได้ดีขึ้น
