
ขอสอบถามเพิ่มเติมครับ
1. สามารถใช้ข้อมูล image และ mask เป็น input ในการ train โดยไม่เตรียมผ่าน encoded pixel ได้ไหมครับ หากได้จะต้องทำการ label class อย่างไรครับ
2. การพัฒนาให้โมเดล neural network ให้สามารถทำนายได้ถูกต้องมากขึ้น ใช้เวลาในการ train , predict น้อยลง มีแนวทางในการพัฒนาอย่างไรบ้างครับ (ปรับปรุง แก้ไขส่วนไหนของโมเดลได้บ้างครับ)
3. จาก workshop ขั้นตอน 2.3 set config มีการกำหนด STEP_PER_EPOCH และ VALIDATION_STEP ให้รันทันในเวลา มีวิธีการคำนวนหาค่านี้อย่างไรครับ เพื่อให้ได้ค่าที่รันทันเวลาสำหรับชุดข้อมูลอื่นๆ จำนวนชั่วโมงที่จำกัดอื่นๆ

สวัสดีครับคุณ @cc8 ตัวโปรเจกต์มีความสำคัญมากครับ
1. จริงๆ คุณ cc8 เข้าใจถูกต้องครับ ตัวโมเดลรับ mask เป็น image อยู่แล้ว ซึ่งในกรณีที่เราไม่ต้องการประหยัดพื้นที่เราสามารถใช้ mask เข้าเป็น input ในการสอนโมเดลได้เลยครับ ไม่จำเป็นต้องทำ Run length encoding โดยใน class FashionDataset ตัว load_mask เราใช้ cv2.imread(image.jpg) ได้เลยครับ ข้ามขั้นตอน decode RLE ไปเลย
2. วิธีการที่ได้รับการยอมรับว่าเพิ่มความแม่นยำได้ดีที่สุดคือ pretraining ดังนั้นถ้าเป็นไปได้คุณ cc8 อาจจะลองดาวโหลดข้อมูลขนาดใหญ่ที่มีลักษณะคล้ายกัน มาสร้างโมเดลให้แม่นยำก่อนแล้ว save weights ไว้ และนำ weights ที่ได้มาเทรนในปัญหาของคุณ cc8 ต่อครับ ผมลองหาใน kaggle ดูอาจจะเช่น dataset นี้ครับ (ลองหาดูเพิ่มเติมได้ครับ) https://www.kaggle.com/mateuszbuda/lgg-mri-segmentation นอกจากนั้นก็มีเรื่องของ Data augmentation (ดูข้อ 4. และดู Workshop Data Augmentation บนการตรวจสอบเบาหวานในดวงตา ของเราเป็นไอเดียได้ครับ) https://www.kaggle.com/ratthachat/aptos-augmentation-visualize-diabetic-retinopathy
3. ปกติ step-per-epoch ทั้ง train และ valid sets เรากำหนดให้เท่ากับจำนวนที่จะอ่านข้อมูลทั้งหมดได้พอดีครับเช่น step_per_epoch = len(train_data)//batch_szie valid_steps = len(valid_data)//batch_size
4. จริงๆ ในปัญหา medical image segmentation, งานวิจัยส่วนใหญ่นิยมใข้ UNet มากกว่า MaskRCNN ผมยังไม่มีโอกาสได้ทำ tutorial แต่ว่าคุณ cc8 ลองดูตัวอย่างจาก notebook นี้ได้ไหมครับ ผมเชื่อว่าใช้งานง่ายกว่า MaskRCNN https://github.com/qubvel/segmentation_models/blob/master/examples/multiclass%20segmentation%20(camvid).ipynb ซึ่งเป็นโมเดลในโน้ตบุคนี้ ก็เป็นโมเดลแบบเดียวกันที่ปัจจุบันตัวผมเองก็ใช้แก้ปัญหาต่างๆ อยู่ มีการโหลด mask แบบไม่ต้องใช้ RLE และรวมทั้งมีตัวอย่างการทำ Data Augmentation ด้วยแทรกอยู่ในโน้ตบุ้คเรียบร้อยแล้วด้วยครับ
สวัสดีครับ @neural-engineer ผมได้ศึกษาโมเดลในข้อ 4 ตามที่คุณแนะนำในโพสต์ก่อนหน้า
ขอสอบถามเกี่ยวกับ ความหมายของคำว่า backbone ที่ใช้ในโมเดลครับว่าหมายถึงอะไร
โดยในโมเดลอธิบายว่า backbone_name: name of classification model (without last dense layers) used as feature extractor to build segmentation model.
แต่ผมยังไม่เข้าใจและมองภาพไม่ออกว่าทำหน้าที่ในโมเดลอย่างไร การพิจารณาเลือกใช้แต่ละชนิดอย่างไร จำเป็นต้องใช้หรือไม่แล้วโมเดลที่มีกับไม่มี backbone แตกต่างกันอย่างไร
ขอรบกวนคุณ @neural-engineer ช่วยอธิบายเพิ่มเติม หรือชี้แนะแหล่งข้อมูลเพิ่มเติมด้วยครับ ขอบคุณที่ให้คำแนะนำและเป็นผู้ให้ความรู้ที่ดีเสมอมาครับ
ยินดีครับคุณ @cc8 , architecture U-Net นั้น simple กว่า MaskRCNN มากๆ แสดงได้ดังรูปนี้ครับ
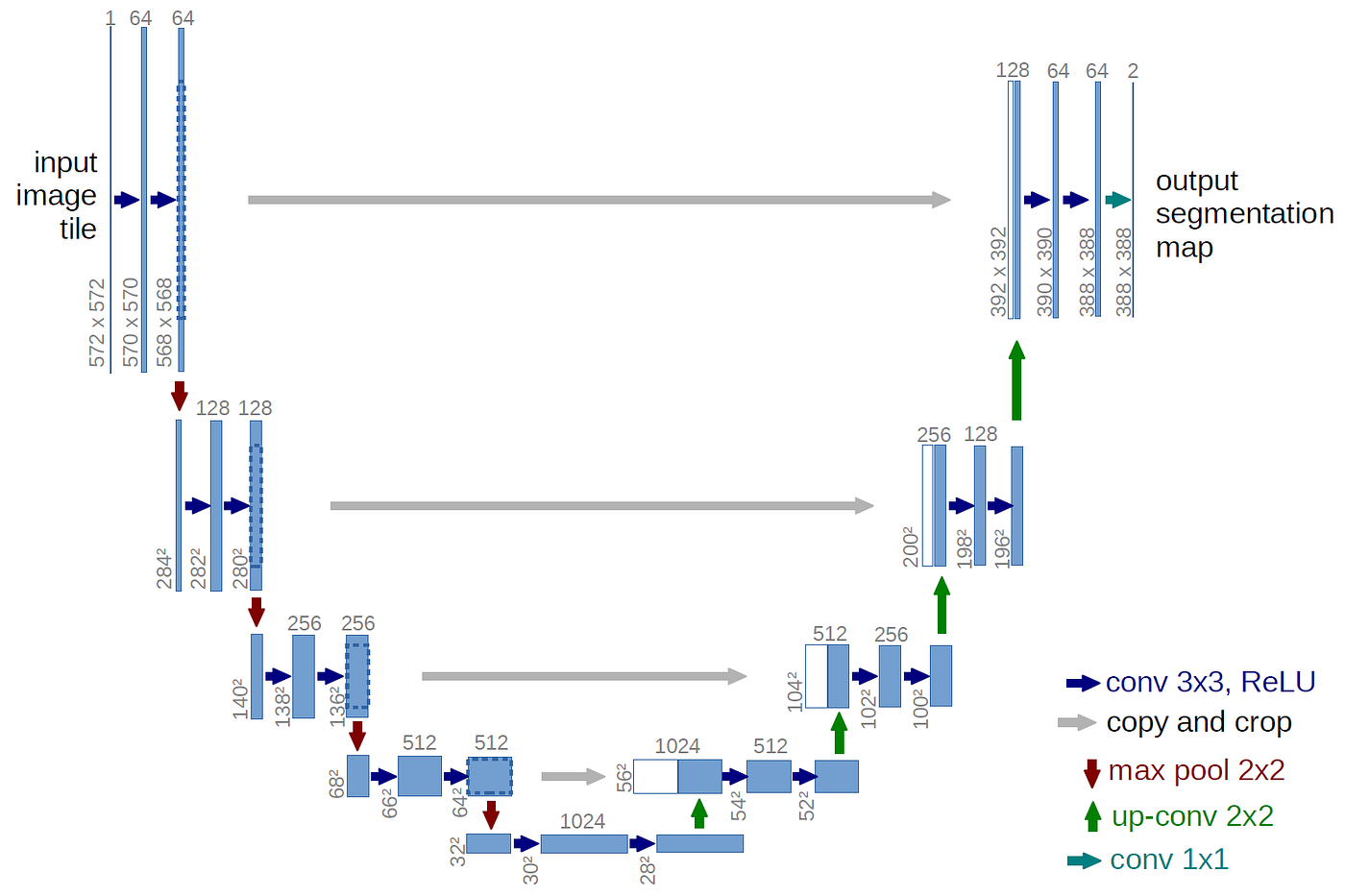
ผู้คิดค้นโมเดลรูปตัว U นี้ ได้นำ convolutional layers มาเรียงต่อกันเสมือนรูปตัว U (มีความสมมาตร) จึงเรียกชื่อว่า U-Net
ภายหลัง นักวิจัยได้ตระหนักว่า ในฝั่งซ้ายของรูปตัว U ซึ่งทำหน้าที่เข้าใจรูปภาพ (สร้าง features ต่างๆ จากรูปภาพ) นั้น สามารถนำโมเดล classification ที่มีอยู่แล้ว (pretrained มาแล้วอย่างดี) มาใส่แทนได้ ทำให้ประสิทธิภาพดีขึ้น และประหยัดเวลาในการเทรนไปอีกเยอะด้วย
โดยโมเดลในครึ่งซ้ายนี้ จะเป็นโมเดลอะไรก็ได้ เช่น VGG, Inception, ResNet หรือ EfficientNet ซึ่งมีประสิทธิภาพในการเข้าใจ image สูงอยู่แล้ว
โมเดลในครึ่งซ้ายซึ่งเป็นหัวใจของ UNet จึงถูกเรียกว่า Backbone ครับ ข้อดีก็คือนำสิ่งที่มีอยู่แล้ว (และดีอยู่แล้ว) มาใช้งานได้เลย นั่นคือ weights ส่วนนี้บางครั้งอาจจะไม่จำเป็นต้อง train ใหม่ เนื่องจาก backbone ถูก pretrained มาก่อนแล้วเป็นอย่างดี
อย่างไรก็ดีเนื่องจากในงาน classification เราต้องการคำตอบเพียงจำนวน class , backbone ต่างๆ จึงถูกออกแบบมาให้มีขนาดเล็กลงเรื่อยๆ (จาก รูปภาพ ที่มีมิติขนาดใหญ่ จนเหลือ เพียง 1มิติ ไม่กี่บิต ที่จะทำนาย class ในปัญหา classification)
เนื่องจากปัญหา Segmentation นั้นมี output เป็น label ราย pixels, output ที่ได้จึงมีขนาดใหญ่เท่ารูปภาพ input ดังนั้นจึงเป็นที่มาของฝั่งขวาของ U-Net ที่เป็นส่วนขยายของ backbone และทำหน้าที่ขยาย output ของ backbone ให้มีขนาดเท่ากับ mask ที่เราต้องการ
การขยายรูปภาพนั้นใช้ Operation ที่เรียกว่า Upsampling ซึ่งมีมาตรฐานอยู่ 2-3 วิธี ซึ่งอธิบายอย่างละเอียดในบทความนี้ครับ : https://distill.pub/2016/deconv-checkerboard/
อธิบาย UNET และ Mask-RCNN เพิ่มเติม https://glassboxmedicine.com/2020/01/21/segmentation-u-net-mask-r-cnn-and-medical-applications/
ขอคำแนะนำครับ
จากที่ได้ฝึกเขียนโมเดล unet ในขั้นตอนของการ train model เมื่อรัน model.fit_generator มี value error
/usr/local/lib/python3.6/dist-packages/keras/utils/data_utils.py:616: UserWarning: The input 798 could not be retrieved. It could be because a worker has died.
ผมลองหาวิธีแก้ไขตามเว็บ https://stackoverflow.com/questions/58446290/userwarning-an-input-could-not-be-retrieved-it-could-be-because-a-worker-has/62078064#62078064
แต่ดูเหมือนจะไม่ได้ผล เมื่อรันใหม่ เกิด value error แบบที่กล่าวข้างต้น จากนั้นเปลี่ยนเป็น error ใหม่
Could not be convert string to float : ‘../input/path_data_train/image_102_train.png’
ขอคำแนะนำครับ value error ในลักษณะนี้เกิดจากอะไร และสามารถแก้ไขได้อย่างไรบ้างครับ
